I have a grouped dataset that contains data that can be repeated at multiple instances within the same group. I need to count the total number of repeated values for each instance that occurs within the same group. Here is a toy set that shows my example:
structure(list(Group = c(1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3,
3), ID = c("non repeating", "repeating", "repeating", "repeating",
"repeating", "non repeating", "repeating", "repeating", "non repeating",
"repeating", "repeating", "repeating", "non repeating")), class = c("tbl_df",
"tbl", "data.frame"), row.names = c(NA, -13L))
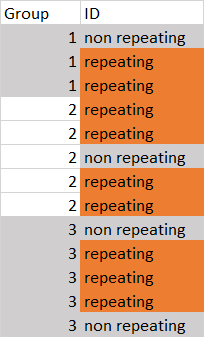
My desired output, because I need to filter these later. would be the following:

What I’ve tried so far is the following:
ex <-
ex_data %>%
group_by(Group) %>%
mutate(
Value = case_when(
ID == lag(ID) ~
1,
TRUE ~ 0
)
) %>%
mutate(
Value = case_when(
ID == lead(ID) ~
1,
TRUE ~ Value
)
) %>%
group_by(ID, .add = T) %>%
mutate(count = sum(Value))
This produces the following, and not what I’m hoping to get as the values are being summed across each group instead of each group and ID

What am I doing wrong here?
>Solution :
library(dplyr)
df |>
mutate(Value = +((lead(ID) == ID | lag(ID) == ID) & ID == "repeating"),
Sum = consecutive_id(Value), .by = Group) |>
mutate(Sum = n(), .by = c(Group, Sum))
# # A tibble: 13 × 4
# Group ID Value Sum
# <dbl> <chr> <int> <int>
# 1 1 non repeating 0 1
# 2 1 repeating 1 2
# 3 1 repeating 1 2
# 4 2 repeating 1 2
# 5 2 repeating 1 2
# 6 2 non repeating 0 1
# 7 2 repeating 1 2
# 8 2 repeating 1 2
# 9 3 non repeating 0 1
# 10 3 repeating 1 3
# 11 3 repeating 1 3
# 12 3 repeating 1 3
# 13 3 non repeating 0 1
The problem you are having is that you are grouping by Group and ID before your last mutate() statement. Your Group == 2 and ID == "repeating" group is size 4, which is why you are getting that value in your output. You need something to make the consecutive values within Group their own distinct group.
To accomplish this I used consecutive_id() which creates a unique identifier for consecutive values and used that to group by in the final mutate().