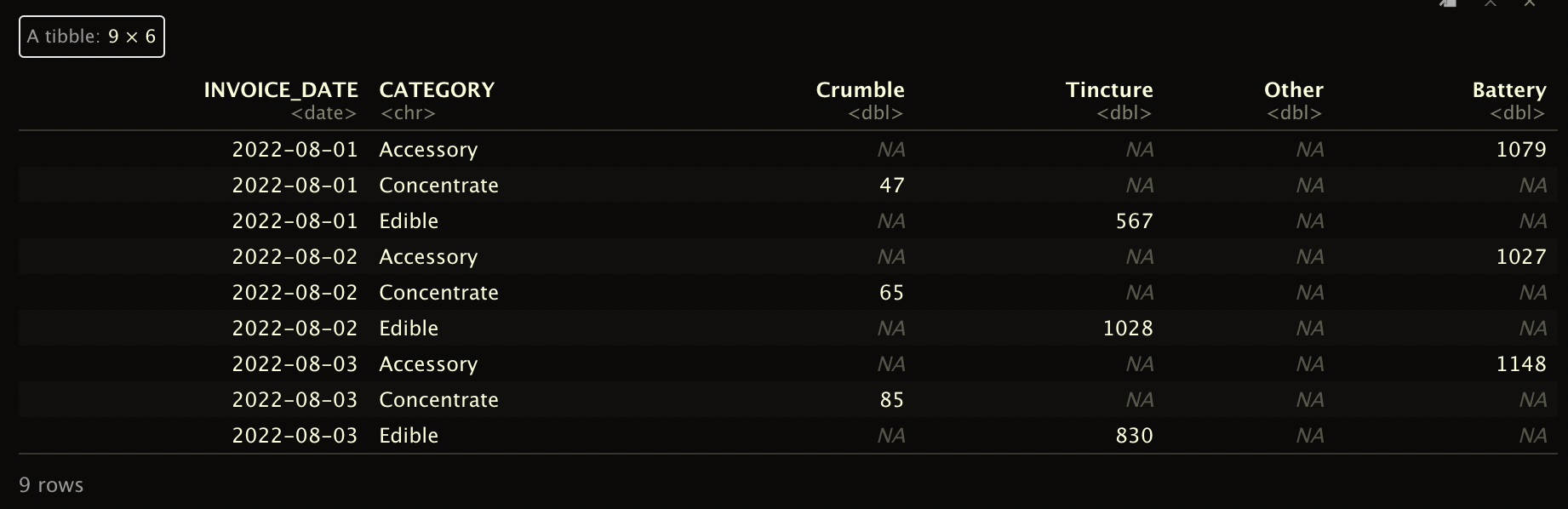
Here is my data frame.
structure(list(INVOICE_DATE = structure(c(19205, 19205, 19205,
19206, 19206, 19206, 19207, 19207, 19207), class = "Date"), CATEGORY = c("Accessory",
"Concentrate", "Edible", "Accessory", "Concentrate", "Edible",
"Accessory", "Concentrate", "Edible"), Crumble = c(NA, 47, NA,
NA, 65, NA, NA, 85, NA), Tincture = c(NA, NA, 567, NA, NA, 1028,
NA, NA, 830), Other = c(NA_real_, NA_real_, NA_real_, NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), Battery = c(1079,
NA, NA, 1027, NA, NA, 1148, NA, NA)), row.names = c(NA, -9L), class = c("tbl_df",
"tbl", "data.frame"))
I can’t find the right verb or set of verbs to do this in R.
How can I remove ‘NA’ values here in a way the squishes the data frame into a nicely formatted table? The CATEGORY column could be deleted. Then all the rest of the columns should fit on one row without any holes.
I can’t do df %>% na.omit() because I end up with a data frame with no observations. The same goes if I try this kind of treatment: filter(is.na()).
>Solution :
library(tidyr)
library(dplyr)
select(df, -CATEGORY) %>%
pivot_longer(-INVOICE_DATE) %>%
filter(!is.na(value)) %>%
pivot_wider()
# A tibble: 3 × 4
INVOICE_DATE Battery Crumble Tincture
<date> <dbl> <dbl> <dbl>
1 2022-08-01 1079 47 567
2 2022-08-02 1027 65 1028
3 2022-08-03 1148 85 830