I have a data frame of presence (1) or absence (NA) of various plants found in different quadrats. I have 5 columns within the data frame of values that I would like to replace the 1’s with. I’d like to end up with 5 different data frames.
Current Data Frame
This is a section of the data frame. Each row is a different plant. The columns L, F, R, N and S are the values I wish to replace the values win the last size columns (‘1_19’, ‘1_20’ etc). Where there are blanks/NAs I want to keep them as blanks.
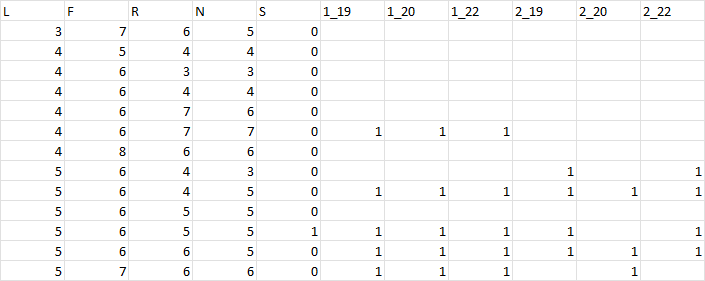
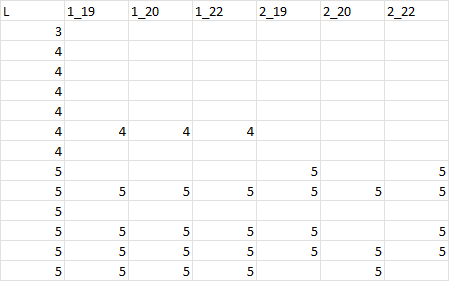
Expected Output
This is an example of the expected output for the L column. I would like to do this for the other columns too as separate dfs.
Data Frame
structure(list(Species = c("Conocephalum conicum", "Mnium hornum",
"Polytrichum formosum", "Oxalis acetosella", "Circaea lutetiana",
"Geum urbanum"), Common.Name = c("Great Scented Liverwort", "Swan's-neck Thyme-moss",
"Bank Haircap", "Wood Sorrel", "Enchanter's-nightshade", "Wood Avens"
), L = c(3L, 4L, 4L, 4L, 4L, 4L), F = c(7L, 5L, 6L, 6L, 6L, 6L
), R = c(6L, 4L, 3L, 4L, 7L, 7L), N = c(5L, 4L, 3L, 4L, 6L, 7L
), S = c(0L, 0L, 0L, 0L, 0L, 0L), Source = c("Hill et al., 2007",
"Hill et al., 2007", "Hill et al., 2007", "Hill et al., 1999",
"Hill et al., 1999", "Hill et al., 1999"), X1_19 = c(NA, NA,
NA, NA, NA, 1L), X1_20 = c(NA, NA, NA, NA, NA, 1L), X1_22 = c(NA,
NA, NA, NA, NA, 1L), X2_19 = c(NA_integer_, NA_integer_, NA_integer_,
NA_integer_, NA_integer_, NA_integer_), X2_20 = c(NA_integer_,
NA_integer_, NA_integer_, NA_integer_, NA_integer_, NA_integer_
), X2_22 = c(NA_integer_, NA_integer_, NA_integer_, NA_integer_,
NA_integer_, NA_integer_), X3_19 = c(NA, NA, NA, NA, NA, 1L),
X3_20 = c(NA_integer_, NA_integer_, NA_integer_, NA_integer_,
NA_integer_, NA_integer_), X3_22 = c(NA_integer_, NA_integer_,
NA_integer_, NA_integer_, NA_integer_, NA_integer_), X4_19 = c(NA_integer_,
NA_integer_, NA_integer_, NA_integer_, NA_integer_, NA_integer_
), X4_20 = c(NA_integer_, NA_integer_, NA_integer_, NA_integer_,
NA_integer_, NA_integer_), X4_22 = c(NA_integer_, NA_integer_,
NA_integer_, NA_integer_, NA_integer_, NA_integer_), X5_19 = c(NA_integer_,
NA_integer_, NA_integer_, NA_integer_, NA_integer_, NA_integer_
), X5_20 = c(NA_integer_, NA_integer_, NA_integer_, NA_integer_,
NA_integer_, NA_integer_), X5_22 = c(NA, NA, NA, NA, NA,
NA), X6_19 = c(NA, NA, NA, 1L, NA, NA), X6_20 = c(NA, NA,
NA, NA, 1L, NA), X6_22 = c(NA, NA, NA, 1L, NA, NA), X7_19 = c(NA_integer_,
NA_integer_, NA_integer_, NA_integer_, NA_integer_, NA_integer_
), X7_20 = c(NA, NA, NA, NA, 1L, NA), X7_22 = c(NA_integer_,
NA_integer_, NA_integer_, NA_integer_, NA_integer_, NA_integer_
), X8_19 = c(1L, NA, 1L, NA, NA, NA), X8_20 = c(NA_integer_,
NA_integer_, NA_integer_, NA_integer_, NA_integer_, NA_integer_
), X8_22 = c(1L, NA, 1L, NA, NA, NA), X9_19 = c(NA, 1L, NA,
NA, NA, NA), X9_20 = c(NA, 1L, NA, NA, NA, NA), X9_22 = c(NA,
1L, NA, NA, NA, NA)), row.names = c(NA, 6L), class = "data.frame")
>Solution :
Using dplyr, this should work :
L=df%>%
rowwise()%>%
mutate_at(.vars=colnames(df)[9:35],funs(replace(., which(.==1), L)))