This question is very similar to this question that I created previously which has an answer, however I’ve come to realize the problem I’m trying to solve has evolved and I figured I should start fresh.
I have two data frames like so:
df1<-structure(list(protocol_no = c("study1", "study2", "study3",
"study4", "study5", "study6", "study7"), status = c("New", "Open",
"Closed", "New", "PI signoff", "Closed", "Open")), row.names = c(NA,
-7L), class = c("tbl_df", "tbl", "data.frame"))
df2<-structure(list(record_id = c(11, 12, 13, 14, 15, 16), protocol_no = c("study1",
"study2", "study3", "study4", "study5", "study6"), status = c("New",
"Closed", "Closed", "New", "PI signoff", "Closed"), form_1_complete = c(0,
0, 0, 0, 0, 0)), row.names = c(NA, 6L), class = "data.frame")
They pretty much reference the same data, but df1 will always be newer and have more rows, whereas df2 is older and has more columns. Also, they will have 20,000+ rows in real life.
I need to update df2 with the new information from df1, this might mean new rows that will be need to be numbered (the record_id column), and it might mean updating the "status" column if its changed.
For instance in this example, the row for study7 is new and needs to be added and given record_id = 17 (because 16 is where that list left off). Additionally the status of study2 changed from Closed to Open (its ‘open’ in df1) so that needs to be changed.
Things that wouldn’t work:
In the previous solution it used binding rows and distinct, but in this scenario since study2 has changed and needs to be updated, that would bind two copies of study2 and have trouble distinguishing which to get rid of.
Output I’m looking for:
A dataframe with all 4 columns, with record_id for everything, one row per protocol (‘protocol_no’), and any status’s that have changed updated to reflect df1. Like so:
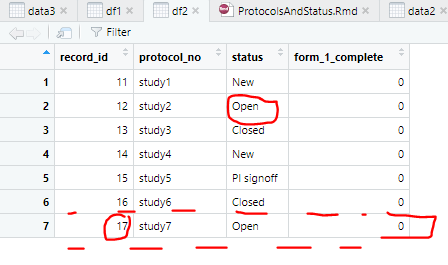
>Solution :
Here, a join would be enough
library(data.table)
setDT(df2)[as.data.table(df1), status := i.status, on = .(protocol_no)]
Or use rows_upsert and use the same code in the other post
library(dplyr)
library(tidyr)
rows_upsert(df2, df1) %>%
fill(record_id) %>%
mutate(record_id = record_id + (rowid(record_id) - 1))
-output
record_id protocol_no status form_1_complete
1 11 study1 New 0
2 12 study2 Open 0
3 13 study3 Closed 0
4 14 study4 New 0
5 15 study5 PI signoff 0
6 16 study6 Closed 0
7 17 study7 Open NA