Task
I need to work with the software plink to do an association study. After inputting all the data and doing all calculations I get a file/ table that looks like this:
CHR SNP A1 A2 TEST AFF UNAFF CHISQ DF P
1 rs10458597 T C TREND 4/230 13/973 0.1565 1 0.6924
1 rs2185539 T C TREND 7/231 0/1000 29.75 1 4.92e-08
1 rs11240767 T C TREND 10/228 15/985 6.206 1 0.01273
1 rs12564807 G A TREND 0/238 0/1000 NA NA NA
1 rs3131972 A G TREND 82/156 259/741 6.618 1 0.0101
1 rs3131969 A G TREND 86/150 253/733 9.629 1 0.001916
1 rs3131967 T C TREND 73/157 212/768 9.407 1 0.002162
1 rs1048488 C T TREND 60/178 203/791 2.435 1 0.1187
1 rs12562034 A G TREND 60/172 256/734 1.008e-06 1 0.9992
I’m only interested in the p-values (last column) and need to generate a Q-Q-Plot. To achieve this I wanted to read in the file with pandas, but I can not find a way to properly read the file.
Previous Attempts
I tried using Excel to interpret the file and generate a proper .csv but since the file is too big, Excel always fails to do so and crashes/ generates only a third of the table.
I have also tried to use the following commands to read the file with pandas, but I get the wrong output:
Commands
df = pd.read_csv(path, sep='\t', engine='python') # attempt 1
df = pd.read_csv(path, sep='\t', lineterminator='\r') # attempt 2
Output:
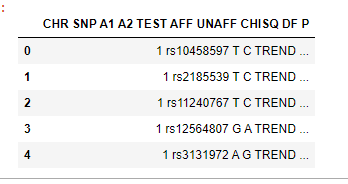
>Solution :
Try it with pd.read_fwf():
df = pd.read_fwf(r'c:\test\test_file.txt')
print(df)
Output:
CHR SNP A1 A2 TEST AFF UNAFF CHISQ DF P
0 1 rs10458597 T C TREND 4/230 13/973 0.156500 1.0 6.924000e-01
1 1 rs2185539 T C TREND 7/231 0/1000 29.750000 1.0 4.920000e-08
2 1 rs11240767 T C TREND 10/228 15/985 6.206000 1.0 1.273000e-02
3 1 rs12564807 G A TREND 0/238 0/1000 NaN NaN NaN
4 1 rs3131972 A G TREND 82/156 259/741 6.618000 1.0 1.010000e-02
5 1 rs3131969 A G TREND 86/150 253/733 9.629000 1.0 1.916000e-03
6 1 rs3131967 T C TREND 73/157 212/768 9.407000 1.0 2.162000e-03
7 1 rs1048488 C T TREND 60/178 203/791 2.435000 1.0 1.187000e-01
8 1 rs12562034 A G TREND 60/172 256/734 0.000001 1.0 9.992000e-01