So I have a .csv file with thousands of rows that have duplicates area names in column A and "Completed" values on column B (which can be "Completed" or "In Progress" in the same area).
| Area | Completed |
|---|---|
| Chicago | In Progress |
| Chicago | Completed |
| Chicago | In Progress |
| Chicago | In Progress |
| San Francisco | Completed |
| San Francisco | Completed |
| San Francisco | Completed |
| San Francisco | Completed |
| Los Angeles | In Progress |
| Los Angeles | In Progress |
| Los Angeles | In Progress |
| Los Angeles | In Progress |
I need to make it so that the end product is the following
| Area | Completed |
|---|---|
| Chicago | Particularly Completed |
| San Francisco | Completed |
| Los Angeles | In Progress |
The idea is to remove the duplicate area values and have the column B be determined by the original values with the following methodology:
- if all of the values in an area are "Completed" then column B is Completed
- if all of the values in an area are "In Progress" then column B is "In Progress"
- if one area contains values "In Progress" and "Completed" then the column B is Particularly Completed
So far I’ve thought about using a python script for this, but want to know if doing this would be possible with just excel as well?
>Solution :
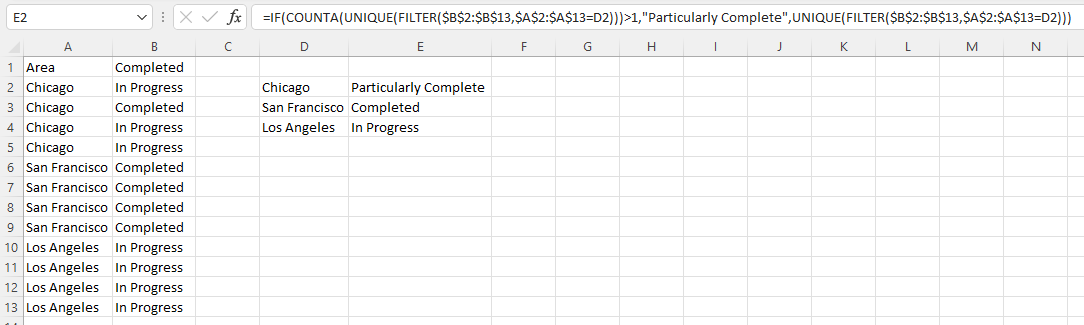
Formula I have used in D2 cell
=UNIQUE(A2:A13)
Then in E2 cell
=IF(COUNTA(UNIQUE(FILTER($B$2:$B$13,$A$2:$A$13=D2)))>1,"Particularly Complete",UNIQUE(FILTER($B$2:$B$13,$A$2:$A$13=D2)))
and drag down till need.