So I am working on testing financial performance of some stocks. I have a pandas column "signal" that by certain logic has "buy" or "sell" signals.
Now these signals occur at random intervals, but whenever they do, almost always they are repeated in a number of consecutive rows.
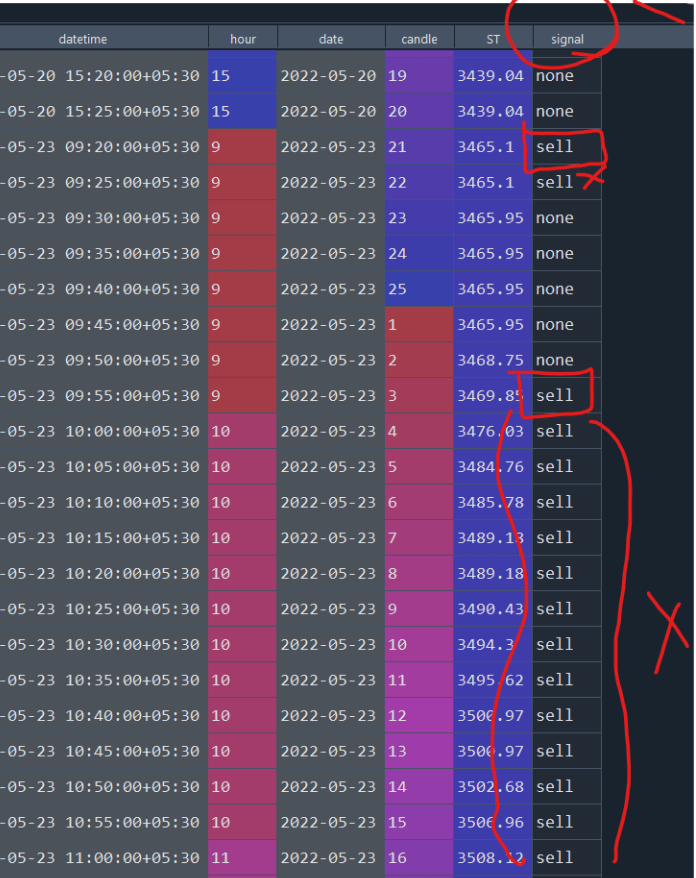
I would like to only keep the 1st instance every time this happens, and remove the consecutive instances of the "buy" / "sell" word. Something like shown below –

>Solution :
Where the signal is equal to sell and the previous value row’s signal is sell, then assign none.
df.loc[df['signal'].eq('sell') & df['signal'].eq(df['signal'].shift()), 'signal'] = 'none'