I have a script that runs on a daily basis to collect data.
I record this data in a CSV file using the following code:
old_df = pd.read_csv('/Users/tdonov/Desktop/Python/Realestate Scraper/master_data_for_realestate.csv')
old_df = old_df.append(dataframe_for_cvs, ignore_index=True)
old_df.to_csv('/Users/tdonov/Desktop/Python/Realestate Scraper/master_data_for_realestate.csv')
I am using append(ignore_index=True), but after every run of the code I still get additional columns created at the start of my CSV. I delete them manually, but is there a way to stop them from the code itself? I looked the function but I am still not sure if it is possible.
My result file gets the following columns added after every run (one at a time, after each run):
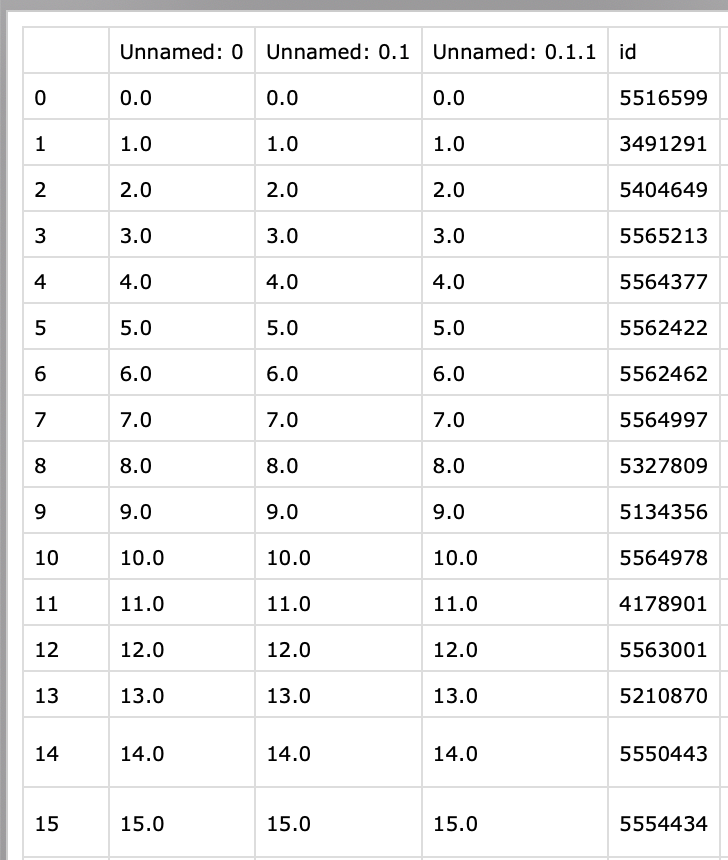
This is really annoying to have to delete everytime.
Update: Data looks like that:

However the id is not unique. Every day it can be repeated. In my case it is not unique. This is an id of an online offer. The offer can be available for one day or for 5 months, or couple of days.
>Solution :
Did you try
to_csv(index=False)