I currently have the following dataframe
data = {'col_a': [['a', 'b'], ['a', 'b', 'c'], ['a'], ['a', 'b', 'c', 'd'], ['a', 'b', 'c'], ['a', 'b', 'c', 'd']],
'col_b':[[1, 3], [1, 0, 0], [4], [1, 1, 2, 0], [0, 0, 5], [3, 1, 2, 5]]}
df= pd.DataFrame(data)
Suppose I work with col_a, I want to resize the lists in col_a in a vectorized manner so that the length of all the sub lists = max length of largest list and I want to fill the empty values with 'None' in the case of col_a. I want the final output to look as follows
col_a col_b
0 [a, b, None, None] [1, 3, nan, nan]
1 [a, b, c, None] [1, 0, 0, nan]
2 [a, None, None, None] [4, nan, nan, nan]
3 [a, b, c, d] [1, 1, 2, 0]
4 [a, b, c, None] [0, 0, 5, nan]
5 [a, b, c, d] [3, 1, 2, 5]
So far I have done the following
# Convert the column to a NumPy array with object dtype
col_np = df['col_a'].to_numpy()
# Find the maximum length of the lists using NumPy operations
max_length = np.max(np.frompyfunc(len, 1, 1)(col_np))
# Create a mask for padding
mask = np.arange(max_length) < np.frompyfunc(len, 1, 1)(col_np)[:, None]
# Pad the lists with None where necessary
result = np.where(mask, col_np, 'None')
This results in the following error
ValueError: operands could not be broadcast together with shapes (6,4) (6,) ()
I feel like I’m close but there’s something that I’m missing here. Please note that only vectorized solutions will be marked as the answer.
>Solution :
Only vectorized solutions will be marked as the answer. -> that’s too bad because no (true) vectorized approach is possible with an array of lists. To this extent, np.frompyfunc is certainly not truly vectorized.
If by "vectorized" you mean without explicit python loop, you could use:
df['out_a'] = pd.Series(pd.DataFrame(df['col_a'].to_numpy().tolist()).to_numpy().tolist())
An alternative with an explicit loop would be:
size = df['col_a'].str.len().max()
df['out_a'] = [l+[None]*(size-len(l)) for l in df['col_a']]
Output:
col_a col_b out_a
0 [a, b] [1, 3] [a, b, None, None]
1 [a, b, c] [1, 0, 0] [a, b, c, None]
2 [a] [4] [a, None, None, None]
3 [a, b, c, d] [1, 1, 2, 0] [a, b, c, d]
4 [a, b, c] [0, 0, 5] [a, b, c, None]
5 [a, b, c, d] [3, 1, 2, 5] [a, b, c, d]
timings
For small lists the "vectorized" and loop solution have very similar timings.
Here for lists with 1 to 10 items:
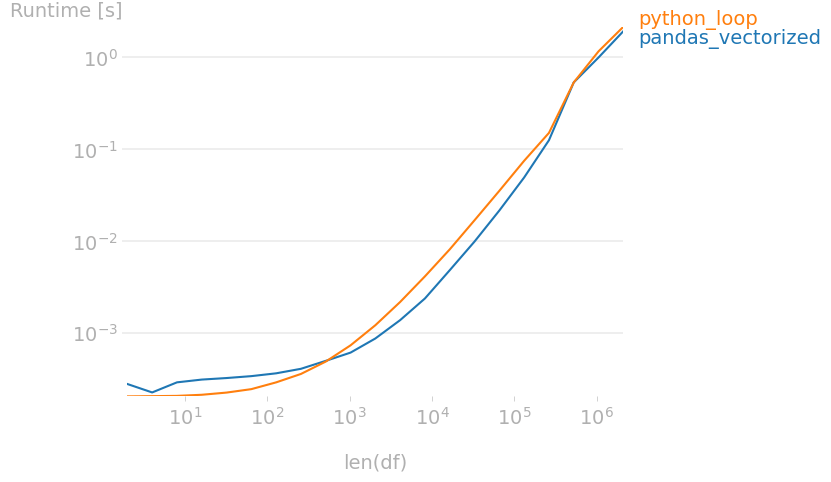
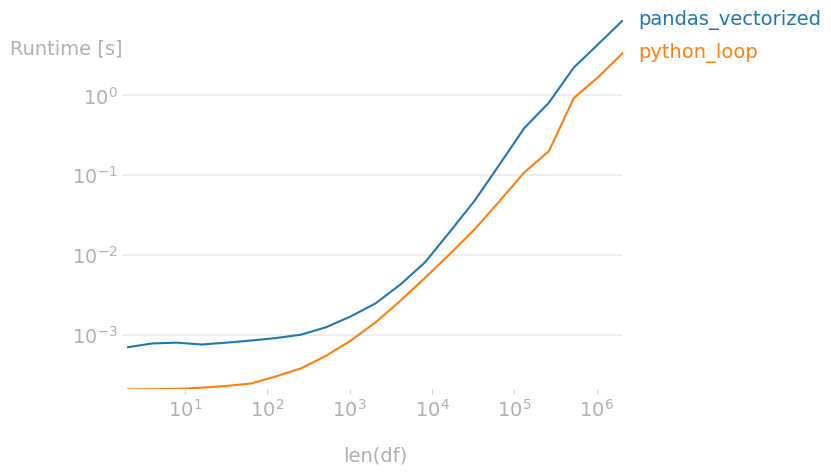
However, when the size of lists increases, the python loop become more efficient.
For list with 0 to 50 items:
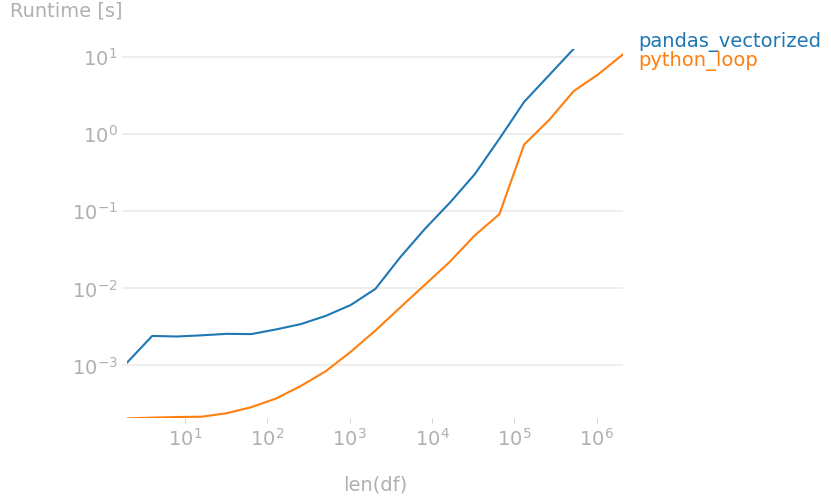
0 to 200 items:
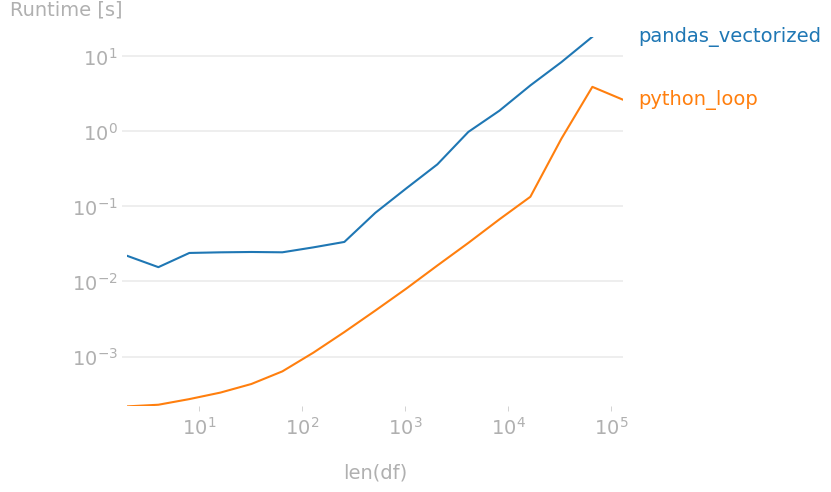
0 to 2000 items:
Code used for the timings:
import pandas as pd
import perfplot
import numpy as np
def pandas_vectorized(df):
df['out_a'] = pd.Series(pd.DataFrame(df['col_a'].to_numpy().tolist()).to_numpy().tolist())
def python_loop(df):
size = df['col_a'].str.len().max()
df['out_a'] = [l+[None]*(size-len(l)) for l in df['col_a']]
MAX_LIST_SIZE = 2000
perfplot.show(
setup=lambda n: pd.DataFrame({'col_a': [['x']*n for n in np.random.randint(0, MAX_LIST_SIZE, size=n)]}),
kernels=[pandas_vectorized, python_loop],
n_range=[2**k for k in range(1, 18)], # upper bound was 22 for small lists
xlabel="len(df)",
equality_check=None,
max_time=10,
)