I want to scrape 3 tables from this url https://ens.dk/sites/ens.dk/files/OlieGas/mp202112ofu.htm
table 1 : oil production
table 2 : gas production
table 3 : water production
doesnt need to include the charts just 3 tables
I have wrote code to scrape links however not sure how to scrape table from links
import io
import requests
import pandas as pd
from bs4 import BeautifulSoup as bs, SoupStrainer
import re
url = "https://ens.dk/en/our-services/oil-and-gas-related-data/monthly-and-yearly-production"
first_page = requests.get(url)
soup = bs(first_page.content)
def pasrse_page(link):
print(link)
df = pd.read_html(link, skiprows=1, headers=1)
return df
def get_gas_links():
glinks=[]
gas_links = soup.find('table').find_all('a')
for i in gas_links:
extracted_link = i['href']
#you can validate the extracted link however you want
glinks.append("https://ens.dk/" + extracted_link)
return glinks
get_gas_links()
output list of links : list of links
{kind=link}
>Solution :
Just use pandas to get the table data and then massage it to your liking.
Here’s how:
import requests
import pandas as pd
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:96.0) Gecko/20100101 Firefox/96.0",
}
page = requests.get("https://ens.dk/sites/ens.dk/files/OlieGas/mp202112ofu.htm", headers=headers).text
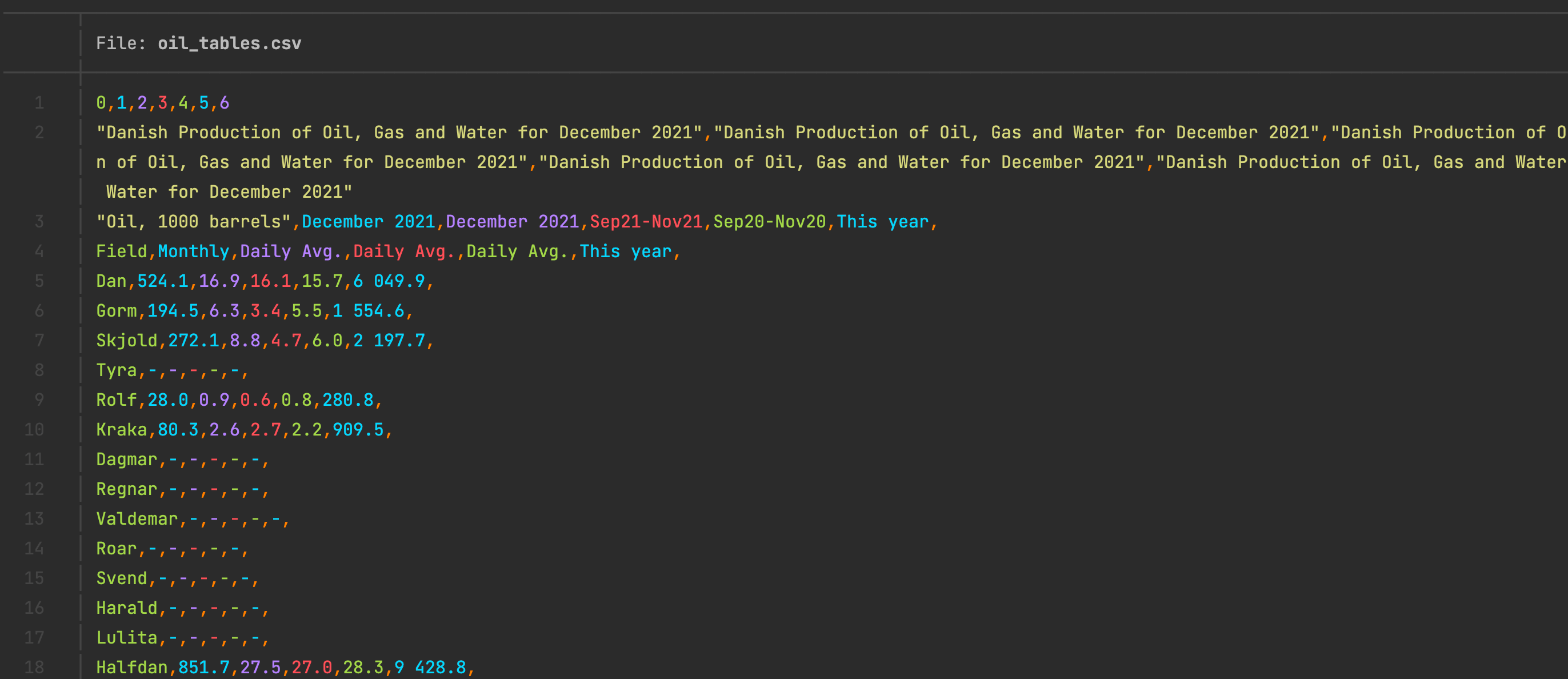
df = pd.concat(pd.read_html(page, flavor="lxml"))
df.to_csv("oil_tables.csv", index=False)
This will get you a .csv file that looks like this: