I have a dataframe like as shown below
td = {966: [('Feat1', -0.04),
('Feat2=True ', -0.02),
('Feat3 <= 20000.00', 0.01),
('Feat4=Power Supply', -0.01),
('Feat5=dada', -0.0)],
879: [('Feat8=Rare', 0.02),
('Feat11=HV', -0.01),
('Feat21=Power Supply', -0.01),
('20000.00 < Feat3 <= 50000.00', 0.01),
('Feat5=dada', -0.01)]}
I would like to do the below
a) Split the tuple within dict based on , comma seperator
b) store the numeric part in value column of dataframe and text part in feature column of dataframe
c) repeat the key values for all values in dataframe (and store it in key column)
I tried the below but it is not efficient/elegant and doesn’t scale for big data of million rows
feature=[]
value=[]
key=[]
for k, v in td.items():
for x in v:
key.append(k)
f, v = x
feature.append(f)
value.append(v)
data_tuples = list(zip(key,feature,value))
pd.DataFrame(data_tuples, columns=['key','feature','value'])
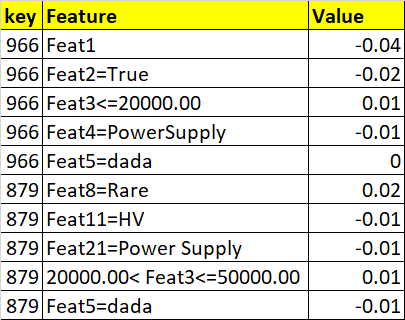
I expect my output to be like as shown below
>Solution :
Use generator comprehension with flatten values and pass to DataFrame constructor:
df = pd.DataFrame()(k,b,c) for k, v in td.items() for b, c in v),
columns=['key','feature','value'])
print (df)
key feature value
0 966 Feat1 -0.04
1 966 Feat2=True -0.02
2 966 Feat3 <= 20000.00 0.01
3 966 Feat4=Power Supply -0.01
4 966 Feat5=dada -0.00
5 879 Feat8=Rare 0.02
6 879 Feat11=HV -0.01
7 879 Feat21=Power Supply -0.01
8 879 20000.00 < Feat3 <= 50000.00 0.01
9 879 Feat5=dada -0.01