I want to make a basic split (see image below) with Python/Pandas.
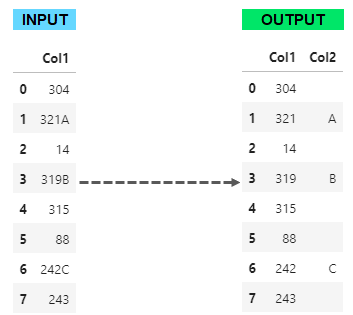
For people who use Excel/PowerQuery, there is a nice function that allow them to do that, Splitter.SplitTextByCharacterTransition.
I tried to make an equivalent in Python using itertools but unfortunately I get a copy of the column "Col1":
import pandas as pd
import itertools
df = pd.DataFrame({'Col1': ['304', '321A', '14', '319B', '315', '88', '242C', '243']})
df['Col2'] = [''.join(a) for b, a in itertools.groupby(df['Col1'])]
>>> df
Col1 Col2
0 304 304
1 321A 321A
2 14 14
3 319B 319B
4 315 315
5 88 88
6 242C 242C
7 243 243
Do you have any suggestions/propositions to fix that, please ?
>Solution :
Let’s try .str.extractall to extract both the number and character then get the first non value in group
out = df.join(df.pop('Col1')
.str.extractall('(\d+)|([a-zA-Z]+)')
.groupby(level=0).first()
.fillna('')
.set_axis(['Col1', 'Col2'], axis=1))
print(out)
Col1 Col2
0 304
1 321 A
2 14
3 319 B
4 315
5 88
6 242 C
7 243