So I have created a dataframe from a dictionary to perform a time series exercise. When I create the dataframe (I’m doing this in Google Colab) the cell runs correctly. but when I do full_df.head(). I get StopIteration error. Does anyone know why this happens?
This is what I have:
df = pd.read_csv('all_stocks_5yr.csv', usecols=["close", "Name"])
gp = df.groupby("Name")
my_dict = {}
for record in gp:
if record[0] in my_dict:
my_dict[record[0]].append(record)
else:
my_dict[record[0]] = [record]
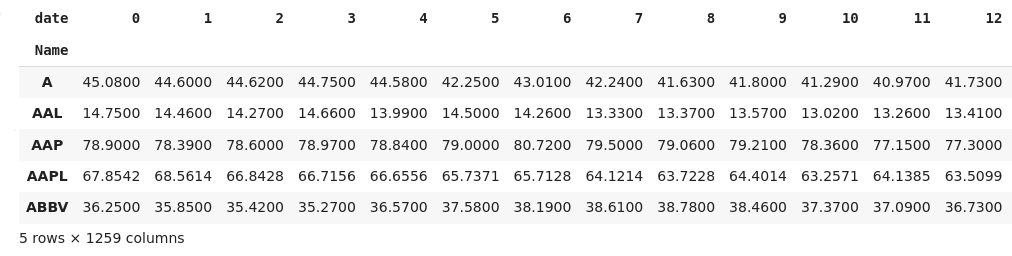
full_df = pd.DataFrame.from_dict(my_dict, orient='index')
full_df.head() #This is where I get the error.
>Solution :
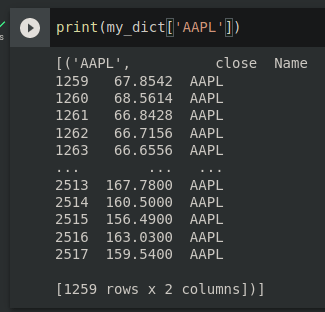
It doesn’t work because you are trying to assign tuples as single column.
The looping over the result of .groupby results in a pair (key, sub_df) where the key is this group name. The sub_df is a DataFrame with all columns and with all values associated with given key. Your loop creates a one element list (where element is the mentioned tuple) for each key in dictionary.
This dictionary would represent a DataFrame with only one column (because each entry in the dictionary is a one-element list) with each row containing tuple of string and dataframe. Pandas has no idea how to translate that into the proper DataFrame.
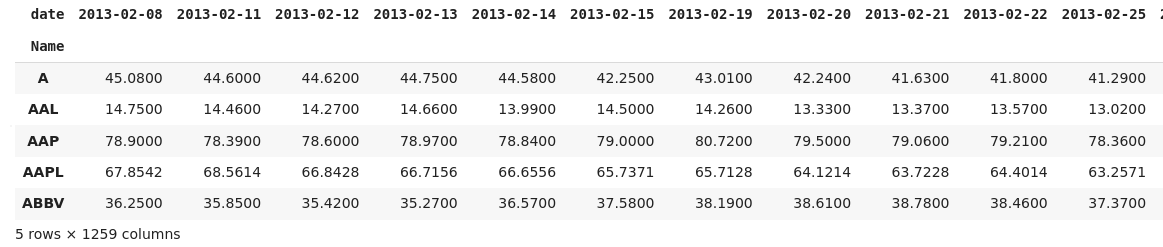
If I understand the intention correctly, then you want to have names in the index and close values in each row. For that it is better to use pivot() function. I found your dataset to try solving it. I recommend loading the date column. You can pivot the loaded DataFrame with:
final_df = df.pivot(columns="date", index="Name", values="close")
final_df.head()
Result:
If you don’t have access to the date column, you can assign increasing values of index in each group with cumcount(). Using following code:
df['date'] = df.groupby('Name').cumcount()
final_df = df.pivot(columns="date", index="Name", values="close")
final_df.head()
You get this: