I have a dataset like these
| Weather | Day | Total | Abo | Noabo |
|---|---|---|---|---|
| 1 | 1 | 500 | 250 | 250 |
| 2 | 2 | 450 | 250 | 200 |
| 1 | 3 | 550 | 350 | 200 |
| 1 | 4 | 530 | 330 | 200 |
| 2 | 5 | 420 | 220 | 200 |
| 3 | 6 | 250 | 200 | 50 |
| 4 | 7 | 150 | 140 | 10 |
| 1 | 8 | 600 | 350 | 250 |
| 3 | 9 | 220 | 200 | 20 |
| 4 | 10 | 110 | 90 | 20 |
| 3 | 11 | 170 | 120 | 50 |
| 3 | 12 | 160 | 150 | 10 |
| 2 | 13 | 380 | 280 | 100 |
| 4 | 14 | 490 | 290 | 200 |
Total is the number of people using pubic transport, abo is people using public transport and have discount, Noabo is people having no discount, but using public transport. Weather shows the situation of weather.
Now I would Like To create A histogram in which the Y AXIS shows the TOTAL and X AXIS shows WEATHER. I want that the bars shows the count number of ABO and NOABO.
I don’t know how to do that and before my question was closed, despite that the suggested question didn’t answered it. they did not answer my question!!!!!
I try this
sns.histplot(data=data, x="weather", y="total", hue=["registered","casual"])
I am expecting something like this
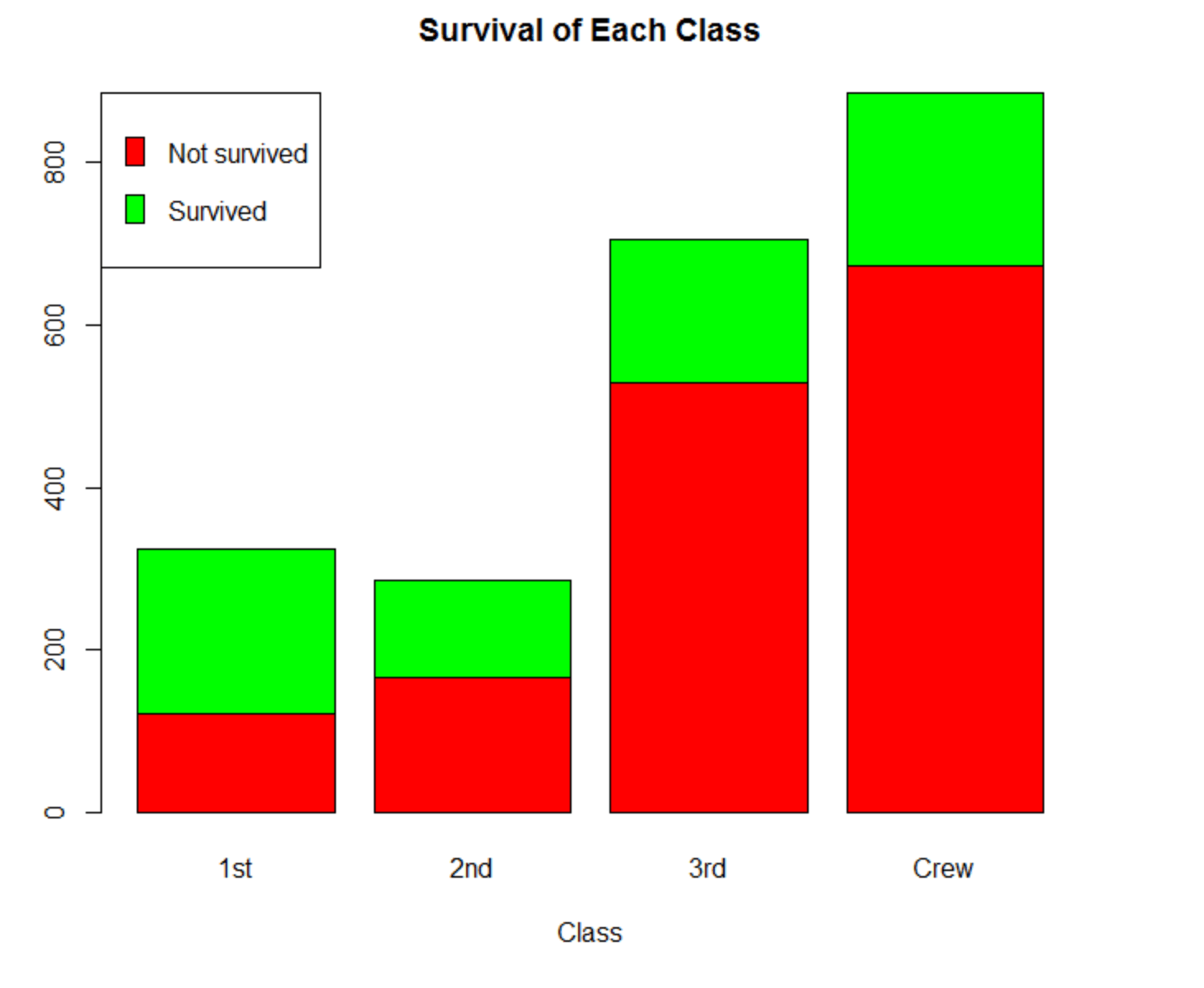
Where survived and not survived represent abo and noabo
>Solution :
You description is not fully clear. For instance what do you want to do with "Day"?
Do you want:
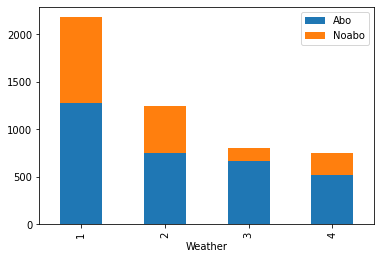
df.set_index('Weather')[['Abo', 'Noabo']].plot.bar(stacked=True)
output:
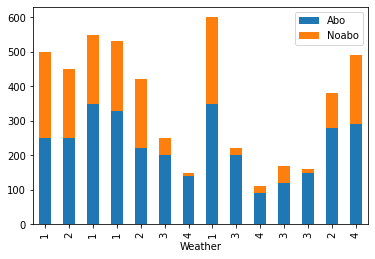
Or maybe:
df.set_index(['Weather', 'Day'])[['Abo', 'Noabo']].plot.bar(stacked=True)
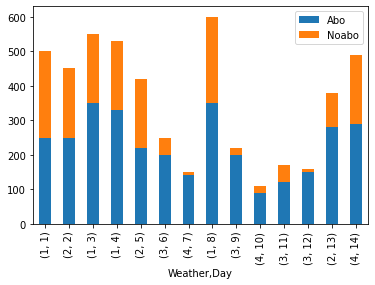
with aggregation as sum on the Weather
df.groupby('Weather')[['Abo', 'Noabo']].sum().plot.bar(stacked=True)
Output: