df is a test dataframe which has 5 rows and 6 columns and it is a subset of a much larger dataframe (dimensions: 1000000 X 30).
df <- data.frame(
Hits = c("Hit1", "Hit2", "Hit3", "Hit4", "Hit5"),
category1 = c("a", "", "b", "a", ""),
category2 = c("c", "", "", "d", "c"),
category3 = c("", "", "e", "f", "f"),
category4 = c("", "", "", "", ""),
category5 = c("i", "", "i", "j", ""))
df looks like this
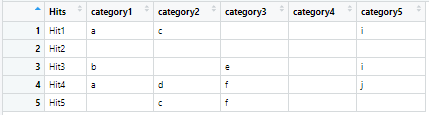
For each column from category1 to category5 I need to retain only the first occurrences of all the unique elements. e.g. For category1, the unique elements are a and b and their first occurrences are in rows 1 and 3 respectively. So rows 1 and 3 should be retained, and so on. The output should look something like this

>Solution :
Using lapply and duplicated you could first replace duplicates per column by "", then filter for rows containing at least one non "" string:
df[-1] <- lapply(df[-1], function(x) {
x[duplicated(x)] <- ""
x
})
df <- df[rowSums(!df[-1] == "") > 0, ]
df
#> Hits category1 category2 category3 category4 category5
#> 1 Hit1 a c i
#> 3 Hit3 b e
#> 4 Hit4 d f j