The sample of the dataset I am working on:
import pandas as pd
# List of Tuples
matrix = [(1, 0.3, 0, 0.7, 30, 0, 50),
(2, 0.4, 0.4, 0.3, 20, 50, 30),
(3, 0.5, 0.2, 0.3, 30, 20, 30),
(4, 0.7, 0, 0.3, 100, 0, 40),
(5, 0.2, 0.4, 0.4, 50, 30, 80)
]
# Create a DataFrame
df = pd.DataFrame(matrix, columns=["id", "terror", "drama", "action", "val_terror", "val_drama", "val_action"])
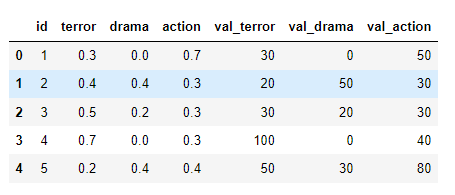
My goal is to create a column referring to the highest value of a genre for each customer (considering only the first three columns at first). For example, in the first row the value for action wins.
But in the second row, we have a tie. Following the df.max(axis=1) function, we will get the first value that it observes as the maximum (which would be for terror). In those cases where there is a tie, I would like to receive the genre with the highest value, for example, in the second row it would be val_drama. Something like:
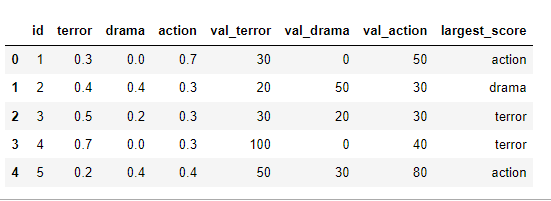
I thought of separating the dataframes into id’s that have equal values and applying the max(axis=1) on both dataframes and then joining. But I’m not succeeding in this task.
>Solution :
Use numpy.where.
In the first two lines I create two subsets just for easier referencing.
Then I use numpy.where to check whether a rows maximum occurs more than once. If yes, I check the other three columns.
import numpy as np
ss1 = df[["terror", "drama", "action"]]
ss2 = df[["val_terror", "val_drama", "val_action"]]
df["largest_score"] = np.where(ss1.eq(ss1.max(axis=1), axis=0).sum(axis=1) > 1,
ss2.idxmax(axis=1).str.replace("val_", ""),
ss1.idxmax(axis=1))