I have a problem of plotting my timeseries datapoints, it just look like unusual, could not manage it due to lack of experience, attached a ss how it looks like and the code also.
Thank you.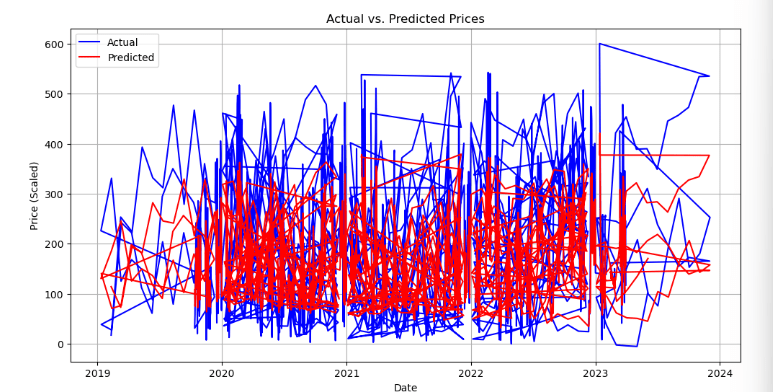
plotting
import matplotlib.pyplot as plt
# Plot actual and predicted values
plt.figure(figsize=(12, 6))
plt.plot(results_df.index, results_df['Actual'], label='Actual', color='blue')
plt.plot(results_df.index, results_df['Predicted'], label='Predicted', color='red')
plt.xlabel('Date')
plt.ylabel('Price (Scaled)')
plt.title('Actual vs. Predicted Prices')
plt.legend()
plt.grid(True)
plt.show()
actual code
import pandas as pd
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from math import sqrt
# Function to convert series to supervised learning
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = pd.DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = pd.concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
# Load dataset
dataset = pd.read_csv('cleaned_merged_dataset.csv', header=0, index_col=0, parse_dates=True)
# Separate the features for scaling
price = dataset.values[:, :1]
wind_gen = dataset.values[:, 1:]
# Create separate scalers for price and wind generation
price_scaler = MinMaxScaler(feature_range=(0, 1))
wind_gen_scaler = MinMaxScaler(feature_range=(0, 1))
# Fit and transform the features
scaled_price = price_scaler.fit_transform(price)
scaled_wind_gen = wind_gen_scaler.fit_transform(wind_gen)
# Combine the scaled features
scaled_values = np.concatenate((scaled_price, scaled_wind_gen), axis=1)
# Frame as supervised learning
reframed = series_to_supervised(scaled_values, 1, 1)
# Split into train and test sets
values = reframed.values
n_train_days = 365 # Use first year for training
train = values[:n_train_days, :]
test = values[n_train_days:, :]
# Split into input and outputs
train_X, train_y = train[:, :-1], train[:, -1]
test_X, test_y = test[:, :-1], test[:, -1]
# Reshape input to be 3D [samples, timesteps, features]
train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1]))
test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1]))
# Define LSTM model
model = Sequential()
model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dense(1))
model.compile(loss='mae', optimizer='adam')
# Fit the model
model.fit(train_X, train_y, epochs=50, batch_size=72, validation_data=(test_X, test_y), verbose=2, shuffle=False)
# Make a prediction
yhat = model.predict(test_X)
# Invert scaling for forecast
yhat_reshaped = yhat.reshape(-1, 1)
inv_yhat = price_scaler.inverse_transform(yhat_reshaped)
inv_yhat = inv_yhat[:, 0]
# Invert scaling for actual
test_y_reshaped = test_y.reshape(-1, 1)
inv_y = price_scaler.inverse_transform(test_y_reshaped)
inv_y = inv_y[:, 0]
# Calculate RMSE
rmse = sqrt(mean_squared_error(inv_y, inv_yhat))
print('Test RMSE: %.3f' % rmse)
# Get the date index for the test set from the original merged dataset
test_dates = dataset.index[n_train_days+1:]
# Create the results DataFrame
results_df = pd.DataFrame(data={"Date": test_dates, "Actual": inv_y, "Predicted": inv_yhat})
# Set 'Date' as the index
results_df.set_index('Date', inplace=True)
I tried to use different techniques before coming here, just could not solve, this small issue. I am just expecting a normal looking timeseries plot.
>Solution :
Looking at the figure, it seems as though the x-axis points are not in order, causing lines to join up unordered timepoints. A quick visual fix is to simply turn the lines off by supplying linestyle='.' when you run plt.plot(...).
To fix the underling cause of unordered timepoints, try applying .sort_index(inplace=True) to your dataframe (assuming the index is the time axis), and if you plot that with lines it should look fine.