I am scrapping some data from this URL
I want to extract Description html div content
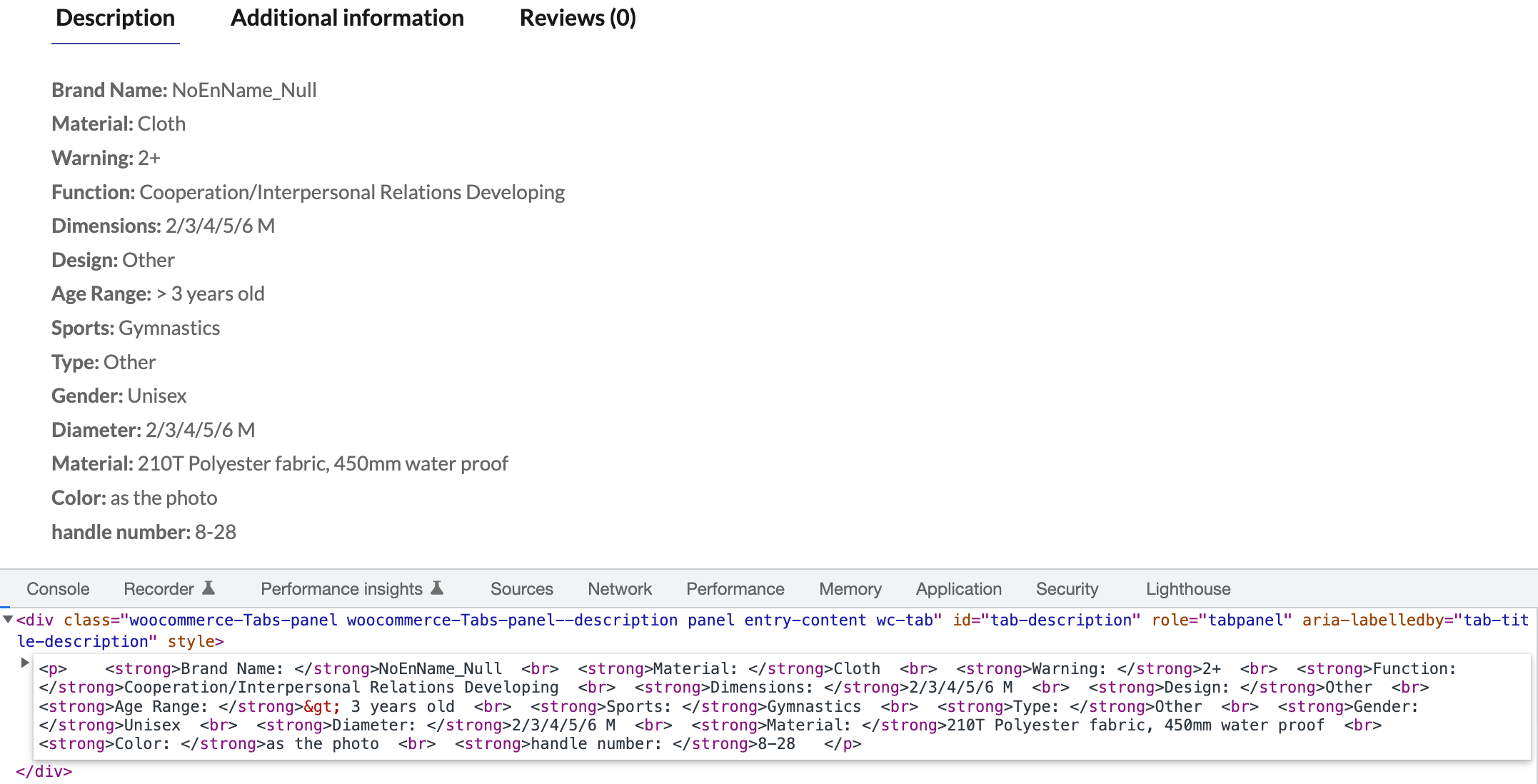
Here is my code
response.xpath("//*[@id='tab-description']/p").extract()
But it return extra ordinary data.

I want the output should be like
<p> <strong>Brand Name: </strong>NoEnName_Null <br> <strong>Material: </strong>Cloth <br> <strong>Warning: </strong>2+ <br> <strong>Function: </strong>Cooperation/Interpersonal Relations Developing <br> <strong>Dimensions: </strong>2/3/4/5/6 M <br> <strong>Design: </strong>Other <br> <strong>Age Range: </strong>> 3 years old <br> <strong>Sports: </strong>Gymnastics <br> <strong>Type: </strong>Other <br> <strong>Gender: </strong>Unisex <br> <strong>Diameter: </strong>2/3/4/5/6 M <br> <strong>Material: </strong>210T Polyester fabric, 450mm water proof <br> <strong>Color: </strong>as the photo <br> <strong>handle number: </strong>8-28 </p>
>Solution :
from bs4 import BeautifulSoup
import requests
r = requests.get('https://bbdealz.com/product/funny-sports-game-2m-3m-4m-5m-6m-diameter-outdoor-rainbow-umbrella-parachute-toy-jump-sack-ballute-play-game-mat-toy-kids-gift/')
soup = BeautifulSoup(r.text, 'html.parser')
info = soup.select_one('#tab-description').select_one('p')
print(info)