I am trying to do pivot of a two categorical Variable (status_type) in python pandas but it is resulting in multiindex dataframe. I would like this to be a normal dataframe but couldn’t figure out how. Would appreciate any help.
import pandas as pd
import numpy as np
# data
test_df = pd.DataFrame({"id": np.arange(0, 8),
"Window": np.random.rand(8),
"status_type" : ["snap","perf","snap","perf","snap","perf","snap","perf"],
"status_level": [1, 2, 20, 35, 10, 5, 42, 9],
})
test_df
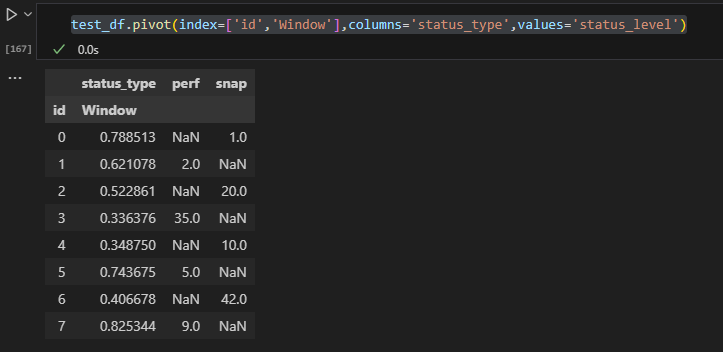
Pivot:
test_df.pivot(index=['id','Window'],columns='status_type',values='status_level')
Result in Multi index df:
I have tried below code to reset it into normal dataframe and remove status_type column but it didn’t work.
(test_df
.pivot(index=['id','Window'], columns='status_type', values='status_level')
.reset_index()
.drop('status_type', axis = 1)
)
>Solution :
A possible solution:
(test_df.pivot(index=['id','Window'],columns='status_type',values='status_level')
.rename_axis(None, axis=1).reset_index())
Output:
id Window perf snap
0 0 0.218674 NaN 1.0
1 1 0.744127 2.0 NaN
2 2 0.888882 NaN 20.0
3 3 0.399161 35.0 NaN
4 4 0.955325 NaN 10.0
5 5 0.938839 5.0 NaN
6 6 0.874510 NaN 42.0
7 7 0.964414 9.0 NaN