when i am studying RNN while running the examples on the following site,
i would like to ask one question.
https://tutorials.pytorch.kr/intermediate/char_rnn_classification_tutorial
According to the site:
1. Model
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
n_hidden = 128
rnn = RNN(n_letters, n_hidden, n_categories)
learning_rate = 0.005
criterion = nn.NLLLoss()
The rnn model with pytorch is like above code
2. Training
The problem was with this part!
According to the site, learning proceeds as follows (in this case it worked fine):
def train(category_tensor, name_tensor):
hidden = rnn.initHidden()
rnn.zero_grad()
for i in range(name_tensor.size()[0]):
output, hidden = rnn(name_tensor[i], hidden)
loss = criterion(output, category_tensor)
loss.backward()
for p in rnn.parameters():
p.data.add_(p.grad.data, alpha=-learning_rate)
return output, loss.item()
But in the pytorch model I recently learned, learning proccess was carried out by optim.step()
So, i also tried the following method (in this case, it didn’t work well):
optimizer = optim.Adam(rnn.parameters(), lr = learning_rate)
def train(category_tensor, name_tensor):
hidden = rnn.initHidden()
rnn.zero_grad()
for i in range(name_tensor.size()[0]):
output, hidden = rnn(name_tensor[i], hidden)
loss = criterion(output, category_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return output, loss.item()
But in this case the training didn’t work properly
3. The result window
for epoch in range(epochs):
...
loss = train(category_tensor, name_tensor)
...
(Result window when this method is used: it seemed learning is not progressing)
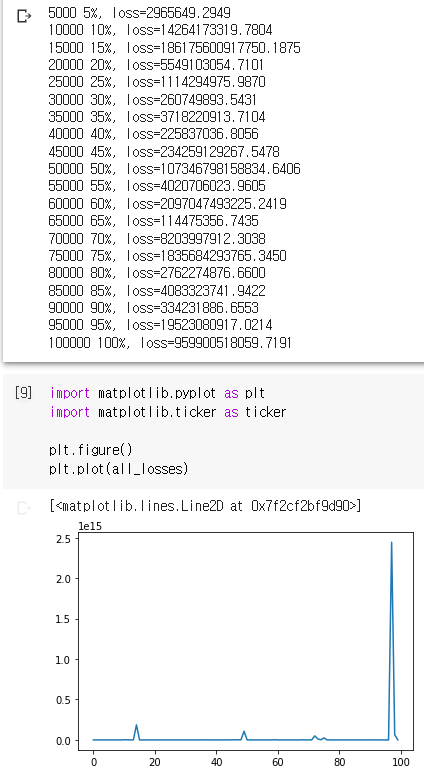
so what is difference between the above optimization method?
and what should i do if i want use optim.step()??
Thanks for reading this long post and I hope you have a good day!!
>Solution :
You are using two different optimization methods. The first one is SGD while the 2nd is Adam.