Python re module does not have atomic grouping, it can be however emulated, for example see this Q&A. I was under the impression that using atomic grouping would be faster than using a simple alternation regex, due to the fact that it will not try all the alternatives in the group. But this does not hold, see below:
import re
import timeit
import random
random.seed(42)
words = ["tricky", "liquid", "sleepy", "crowded", "half", "secretary", "roll", "educate", "medical", "closed",
"unaccountable", "earthy", "permit", "pleasant", "confuse", "enter", "land", "encourage", "connection",
"mindless", "spicy",
"cracker", "twist"]
atomic_group = re.compile(
r"(?=(unaccountable|l(?:and|iquid)|half|t(?:ricky|wist)|roll|p(?:ermit|leasant)|s(?:picy|ecretary|leepy)|e(?:ducate|arthy|n(?:ter|courage))|m(?:indless|edical)|c(?:r(?:owded|acker)|on(?:fuse|nection)|losed)))\1")
non_atomic_group = re.compile(
r"(?:unaccountable|l(?:and|iquid)|half|t(?:ricky|wist)|roll|p(?:ermit|leasant)|s(?:picy|ecretary|leepy)|e(?:ducate|arthy|n(?:ter|courage))|m(?:indless|edical)|c(?:r(?:owded|acker)|on(?:fuse|nection)|losed))")
sentence = " ".join(random.choices(words, k=10000))
print(timeit.timeit("atomic_group.findall(sentence)",
setup="from __main__ import atomic_group, sentence",
number=10))
print(timeit.timeit("non_atomic_group.findall(sentence)",
setup="from __main__ import non_atomic_group, sentence",
number=10))
Output
0.036498754999999994
0.028361783
The same behaviour is observed for larger datasets as is shown in the following plot:
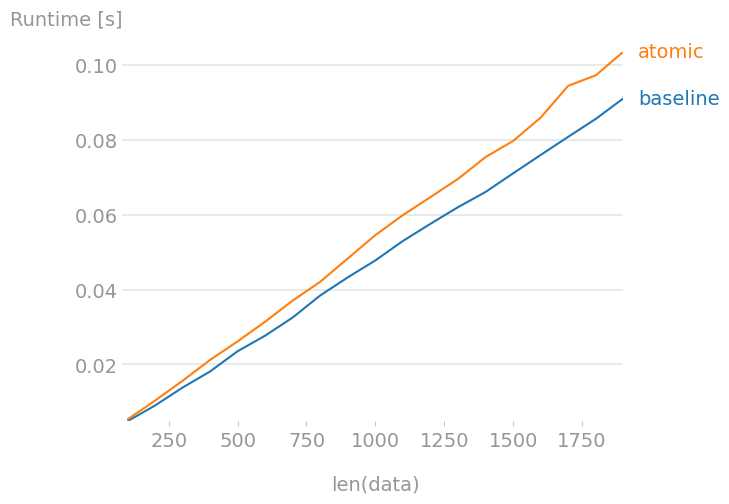
In the plot len(data) represents an increasing number of sentences (strings formed by 60 words). The code to reproduce it can be found here.
Is my assumption incorrect? On a more general note how can I write a regular expression (in Python) that will only try one of the branches in an alternation regex and none of the others?
>Solution :
Your assumption is not correct. The whole point of atomic patterns is to prevent backtracking into the pattern.
The atomic_group pattern is of (?=(...))\1 type in your code and the non-atomic one is of (?:...) type. So, the first one already loses to the second one due to the use of a capturing group, see capturing group VS non-capturing group.
Besides, you need to match the strings twice with the atomic_group pattern, first, with the lookahead, second, with the backreference.
So, only use this techinque when you need to control backtracking inside a longer pattern.