I realized of something very weird today, I have a .csv file which contains a df that is displayed as shown below when open with Excel:
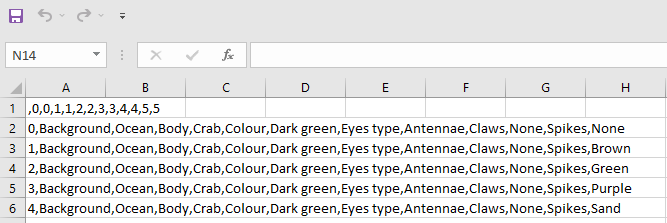
One could think after executing the following code on Python3x:
import pandas as pd
metadata_file_path = r'C:\Users\ResetStoreX\Pictures\Metadata.csv'
df_metadata = pd.read_csv(metadata_file_path, index_col=0)
print(df_metadata)
The expected output should be this one down below:
0 0 1 1 2 2 3 3 4 4 5 5
0 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes None
1 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Brown
2 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Green
3 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Purple
4 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Sand
However, it ends up being this one instead:
0 0.1 1 1.1 2 2.1 3 3.1 4 4.1 5 5.1
0 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes None
1 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Brown
2 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Green
3 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Purple
4 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Sand
As can be seen, the columns with the same name were modified by Pandas (or Python) when imported, so it was added 0.1 to the next column with the same name of the previous one.
I don’t understand why this happens, and if possible, I would like to know a way of preventing this unexpected modification.
>Solution :
Pandas read_* methods always prevent duplicated columns names, because is problem with selecting.
If use df[0] it select both columns, not one.
For original columns names is possible use:
df.columns = df.columns.str.split('.').str[0].astype(int)
Another idea is used first values before . for grouping without change columns names:
row = 0
d = {x.iat[0]: x.iat[1] for name, x in df.iloc[row].groupby(lambda x: x.split('.')[0], level=0)}