I’m trying to execute the same function with 4 different inputs in parallel.
it works when the total input is less than 10^5, but when it gets bigger it starts to work concurrently.
def subList_process(instance):
print("start")
l = List(dataSet=instance)
l.shuffle_set()
l.sort_set()
print("done")
if __name__ == '__main__':
p=[]
p.append(multiprocessing.Process(target=subList_process,args=(lists[0],)))
p.append(multiprocessing.Process(target=subList_process,args=(lists[1],)))
p.append(multiprocessing.Process(target=subList_process,args=(lists[2],)))
p.append(multiprocessing.Process(target=subList_process,args=(lists[3],)))
for process in p : process.start()
for process in p : process.join()
and here is the output with two different data sizes:
- 10^4
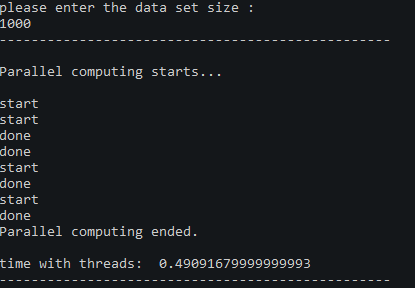
- 10^6
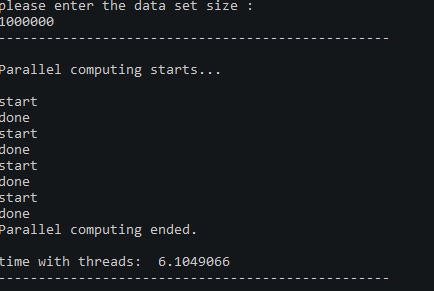
can i get an explanation of what’s happening when the data size is relatively big?
and how can i fix it?
>Solution :
Multiprocessing needs to serialize (i.e. pickle) the arguments in the main process and send it to the subprocesses. Since your parallelized function is quite fast, the function finished before the next set of input arguments was serialized.
Edit: Replying to your comment
There are no good ways to get around this, but here are some alternatives:
- Try to transfer instructions on how to create arguments instead of the arguments themselves. If your inputs are for instance generated using a creator function, just call the creator function in the subprocess as well.
- Store arguments on the disk if you only create them once and read them relatively frequently. Particularly if you have an SSD-drive you could read the arguments (e.g. in the form of pickle-files) from the disk in the subprocess. This could be faster.