Say I have a dataframe (df) with a total of 2 columns and 40 rows. The first column have duplicated key/ID values and the second contains 20 positive values, followed by 20 negative ones.
Because of this, I decided to go for a diverging bar chart. But whenever I plotted the chart, the X-axis text was being displayed twice — like, with one set (e.g. the first 20 positive values) overlapping the other (e.g. the last 20 negative values). My solution was to use scale_x_discrete (); in part because it looked way better this way, too.
But I still needed to show the X-axis text. I thought about displaying it at the base of one set of bars (the positive ones). Like this:
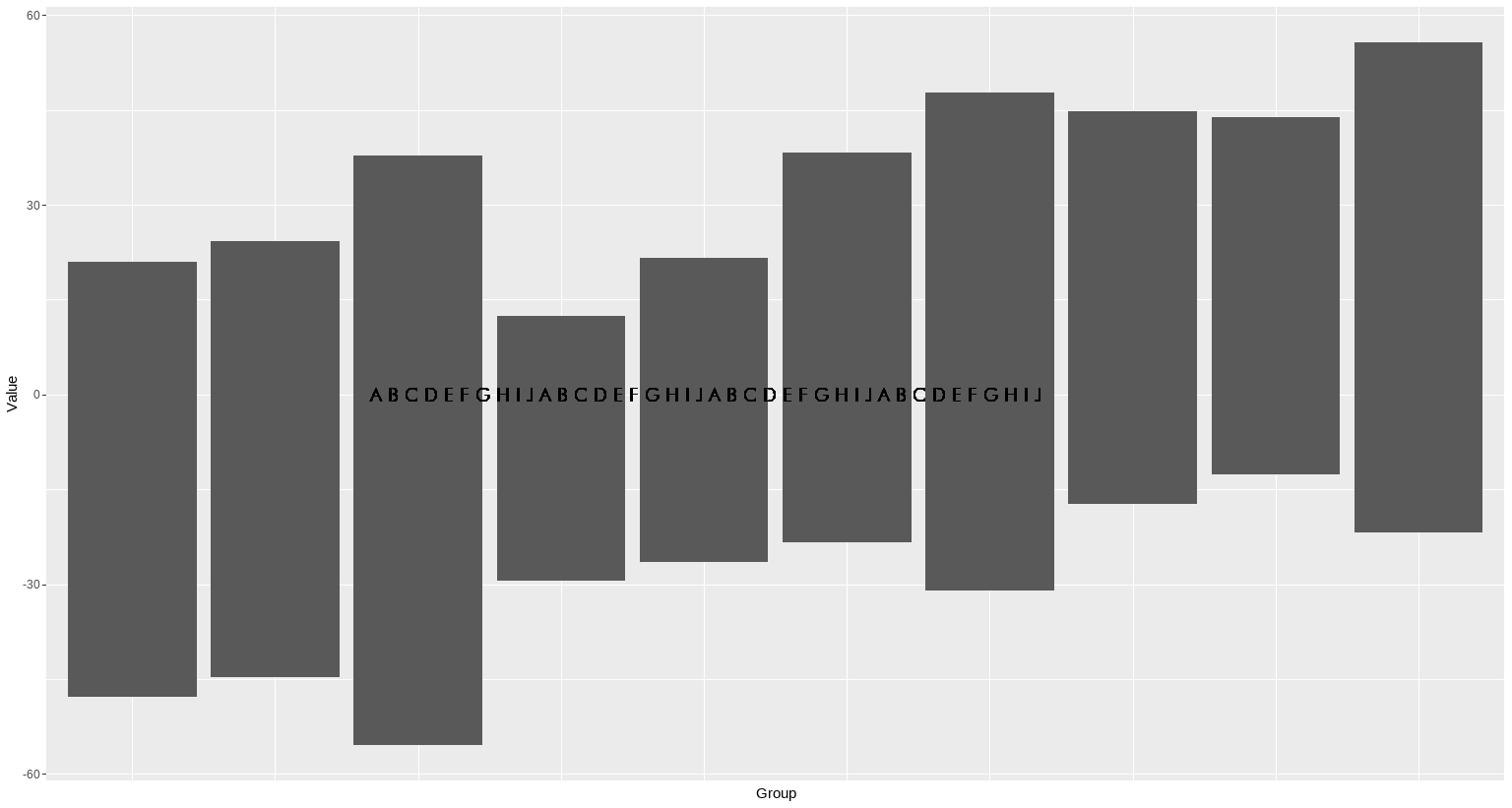
(But with the annotated text more spaced, fitting the center of each bar).
But when I try to do this as shown in my sample code below, the key values (col1) are still being overlapped! Or maybe they just look like they’re in bold… Either way, I can’t get this right =//
What could I do?
DATA
#Sample df:
structure(list(col1 = c("A", "B", "C", "D", "E", "F", "G", "H",
"I", "J", "A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "A",
"B", "C", "D", "E", "F", "G", "H", "I", "J", "A", "B", "C", "D",
"E", "F", "G", "H", "I", "J"), col2 = c(18.5817806317937, 28.1916172143538,
8.66620996058919, 12.0227236610372, 24.4170182822272, 29.3641960325185,
28.7800777778029, 23.1192238365766, 15.7798075131141, 2.86982706259005,
19.6636101899203, 27.5613576434553, 3.76174484286457, 9.56581128691323,
23.3280192685779, 8.42091225110926, 16.01897605462, 20.6576479838695,
5.26960676000454, 21.3152553031687, -1, -14.7368421052632, -10.1578947368421,
-2.52631578947368, -13.2105263157895, -25.4210526315789, -5.57894736842105,
-4.05263157894737, -26.9473684210526, -28.4736842105263, -22.3684210526316,
-7.10526315789474, -19.3157894736842, -23.8947368421053, -17.7894736842105,
-30, -11.6842105263158, -8.63157894736842, -20.8421052631579,
-16.2631578947368)), class = "data.frame", row.names = c(NA,
-40L))
#Sample plot:
ggplot(df, aes(x = reorder (col1, col2), y = col2)) +
geom_bar(stat = "identity", show.legend = FALSE) +
geom_text (aes (x = 5, y = 0.07, label = paste (col1, collapse = " "), family = "Futura"), color = "black", size = 5) +
xlab("Group") +
ylab("Value") +
theme (axis.text.x = element_blank(), axis.ticks.x = element_blank())
>Solution :
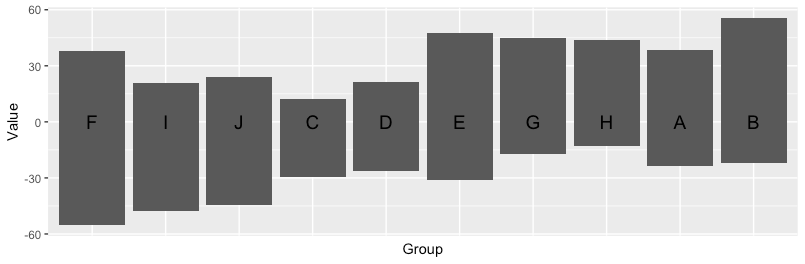
I find it easier to work with different layers in ggplot2 if we prepare the variable order before it gets to ggplot. Here I make col1 an ordered factor based on col2 (by default using the median value).
library(ggplot2); library(dplyr)
df |>
mutate(col1 = forcats::fct_reorder(col1, col2)) |>
ggplot(aes(x = col1, y = col2)) +
geom_bar(stat = "identity", show.legend = FALSE) +
geom_text(aes(y = 0.07, label = col1), size = 5,
data = distinct(df, col1)) + # only need one obs per col1
xlab("Group") +
ylab("Value") +
theme(axis.text.x = element_blank(), axis.ticks.x = element_blank())