I’m looking for a simple way to get rid of the key column of the right table after merging it with another data frame:
import pandas as pd
users = pd.DataFrame({"id": [1,2,3], "name": ["Mark", "Elon", "Jeff"]})
orders = pd.DataFrame({"id": [1,2,3,4,5,6], "user_id": [2,3,2,1,1,3]})
orders_full = pd.merge(left=orders, right=users, how="left", left_on="user_id", right_on="id")
orders_full
This is the result:
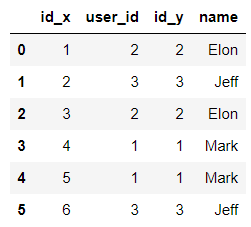
I guess there is a pythonic elegant code to have better column names as result (avoid renaming e and dropping each column manually)
good solution: id, user_id, name
even better: order_id, user_id, user_name
>Solution :
To get around the id_x/id_y issue, you can set_index on the appropriate columns and use join instead:
orders_full = (
orders
.set_index('user_id')
.join(users.set_index('id'), how='left')
.reset_index()
)
Output:
user_id id name
0 1 4 Mark
1 1 5 Mark
2 2 1 Elon
3 2 3 Elon
4 3 2 Jeff
5 3 6 Jeff
To finish with your desired column names, you will have to do a rename e.g.
orders_full = (
orders
.set_index('user_id')
.join(users.set_index('id'), how='left')
.reset_index()
.rename(columns={'id':'order_id', 'name':'user_name'})
)
Output:
user_id order_id user_name
0 1 4 Mark
1 1 5 Mark
2 2 1 Elon
3 2 3 Elon
4 3 2 Jeff
5 3 6 Jeff