Given a df as follows:
df <- structure(list(group = c("A", "A", "A", "A", "A", "B", "B", "B",
"B"), pred_val = c(22.52, 21.87, 31.45, 21.45, 19.99, 13.96,
15.97, 6.5, 19.89), actual_val = c(21L, 21L, 21L, 21L, 21L, 16L,
16L, 16L, 16L)), class = "data.frame", row.names = c(NA, -9L))
Out:
group pred_val actual_val
A 22.52 21
A 21.87 21
A 31.45 21
A 21.45 21
A 19.99 21
B 13.96 16
B 15.97 16
B 6.50 16
B 19.89 16
Let’s say I’ll need to groupby group column then create a new column acc_level, more specifically, for each group, if pred_val is in the range of actual_val ±2, then returns good as acc_level, if in the range of actual_val ±5, but not in actual_val ±2, then returns medium, outer of those ranges, then return poor.
How could I achieve that use dplyr or other packages in R? Thanks.
Pseudo code:
df %>% group_by(group) %>%
mutate(acc_level = case_when((pred_val isin actual_val ±2) ~ 'good', (pred_val isin actual_val ±5) ~ 'medium', otherwise ~ 'poor'))
Expected output:
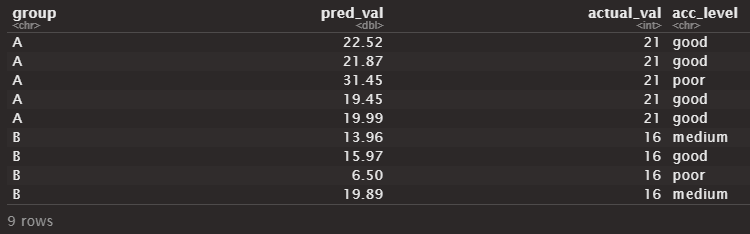
>Solution :
df %>%
group_by(group) %>%
mutate(acc_level =abs(pred_val-actual_val),
acc_level = case_when( acc_level<=2~'good',
acc_level <=5~'medium', TRUE~'poor'))
# A tibble: 9 x 4
# Groups: group [2]
group pred_val actual_val acc_level
<chr> <dbl> <int> <chr>
1 A 22.5 21 good
2 A 21.9 21 good
3 A 31.4 21 poor
4 A 21.4 21 good
5 A 20.0 21 good
6 B 14.0 16 medium
7 B 16.0 16 good
8 B 6.5 16 poor
9 B 19.9 16 medium