I am new to modeling so please bear with me, but am using statsmodels mixedlm as follows:
model = smf.mixedlm("value ~ categorical_variable", data, groups=data[year_identifier])
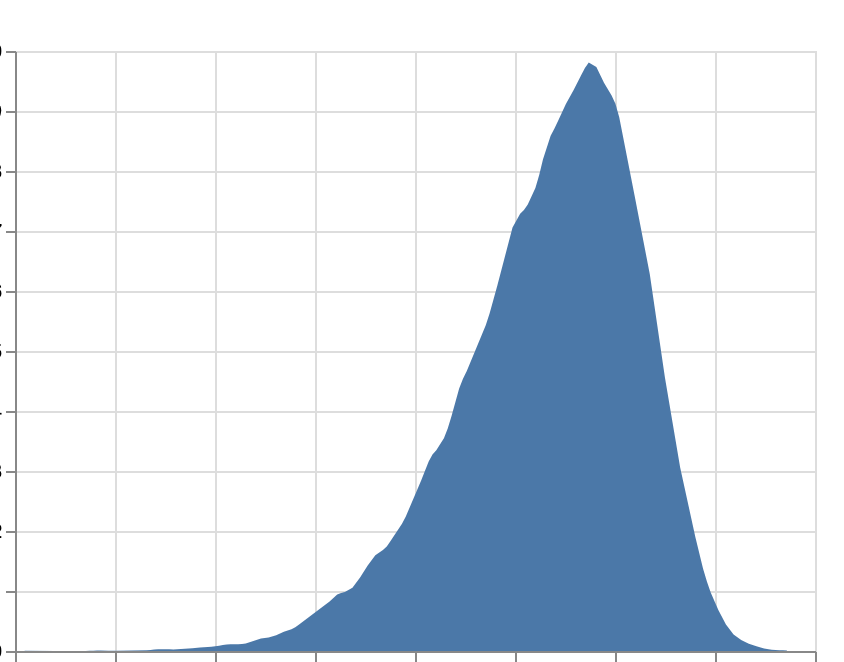
When I plot the residuals I have a slightly left skewed distribution:
I tried to transform my response variable so that it was a skewed normal with a custom skew parameter:
# Define the custom skew-normal distribution with a custom skew parameter
skew_parameter = -4
# Transform response variable using the inverse CDF
data["transformed_value"] = stats.skewnorm.ppf(
stats.norm.cdf(
x=np.array(data["value"].values),
),
skew_parameter,
)
And it resulted in all np.inf values.
I then tried to transform by adjusting the loc and scale values:
# Transform response variable using the inverse CDF
data["transformed_value"] = stats.skewnorm.ppf(
stats.norm.cdf(
x=np.array(data["value"].values),
loc=np.mean(data["value"]),
scale=np.std(data["value"]),
),
skew_parameter,
)
This provided a transformed array, but when I plotted the residuals the distribution was actually worse and when I transformed them back, using the formula below, The values did not look correct at all:
result.params['Intercept'] = stats.skewnorm.cdf(result.params['Intercept'], skew_parameter)
result.params['categorical_variable[T.value]'] = stats.skewnorm.cdf(result.params['categorical_variable[T.value]'], skew_parameter)
Can anyone suggest what to do in this situation?
Perhaps I am not transforming correctly, or, maybe there is a better way to deal with a left-skewed normal distribution?
Thank you!!!
>Solution :
Let’s break down the situation and address the issues step-by-step.
Left-skewed residuals: Ideally, the residuals of a regression model should be normally distributed. If they are not, it may indicate non-linearity, omitted variables, or other issues in the model. Transformations can sometimes help in achieving this. However, before jumping to transformations, it might be useful to consider other model specifications, adding interaction terms, or including other predictors.
Transformations using skew-normal distribution: The idea of using the skew-normal distribution is interesting, but it’s a bit tricky to implement correctly. The primary issue arises from the fact that you’re using the inverse CDF (percent-point function, or ppf) of the skew-normal distribution on the CDF values of the normal distribution of your data. This can lead to unexpected results, especially if the skew parameter is extreme.
Values becoming np.inf: The np.inf values arise because, for some values of the skew parameter and the data’s values, the ppf function returns infinity. This is especially true when the CDF values approach 1.
Transforming back: It’s crucial to remember that transforming data changes the scale and distribution. When you revert the transformed parameters back to the original scale, they may not always make sense, especially if the transformation was not appropriate.
Suggestions:
Alternative Transformations: Before using the skew-normal distribution, consider simpler transformations such as the square root, logarithm, or Box-Cox transformation. The Box-Cox transformation, in particular, can be useful as it determines the best power transformation of the data that reduces skewness.
Model Specification: Consider adding other predictors, polynomial terms, or interaction terms to the model. Sometimes, the residuals’ skewness can be addressed by specifying the model differently.
Use Quantile Regression: If the primary concern is about the distribution of residuals, and transformations don’t seem to work, consider using quantile regression. It does not make assumptions about the residuals’ distribution.
Re-evaluate the Need for Transformation: Sometimes, slight deviations from normality in the residuals might not be a big issue, especially if the sample size is large.