So here’s my simple example (the json field in my actual dataset is very nested so I’m unpacking things one level at a time). I need to keep certain columns on the dataset post json_normalize().
https://pandas.pydata.org/docs/reference/api/pandas.json_normalize.html
Start:

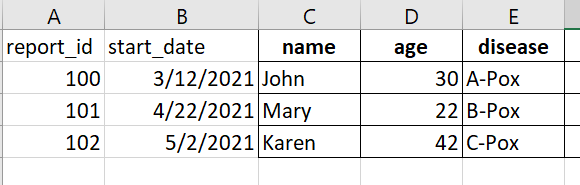
Expected (Excel mockup):
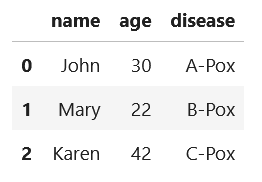
Actual:
import json
d = {'report_id': [100, 101, 102], 'start_date': ["2021-03-12", "2021-04-22", "2021-05-02"],
'report_json': ['{"name":"John", "age":30, "disease":"A-Pox"}', '{"name":"Mary", "age":22, "disease":"B-Pox"}', '{"name":"Karen", "age":42, "disease":"C-Pox"}']}
df = pd.DataFrame(data=d)
display(df)
df = pd.json_normalize(df['report_json'].apply(json.loads), max_level=0, meta=['report_id', 'start_date'])
display(df)
Looking at the documentation on json_normalize(), I think the meta parameter is what I need to keep the report_id and start_date but it doesn’t seem to be working as the expected fields to keep are not appearing on the final dataset.
Does anyone have advice? Thank you.
>Solution :
as you’re dealing with a pretty simple json along a structured index you can just normalize your frame then make use of .join to join along your axis.
from ast import literal_eval
df.join(
pd.json_normalize(df['report_json'].map(literal_eval))
).drop('report_json',axis=1)
report_id start_date name age disease
0 100 2021-03-12 John 30 A-Pox
1 101 2021-04-22 Mary 22 B-Pox
2 102 2021-05-02 Karen 42 C-Pox