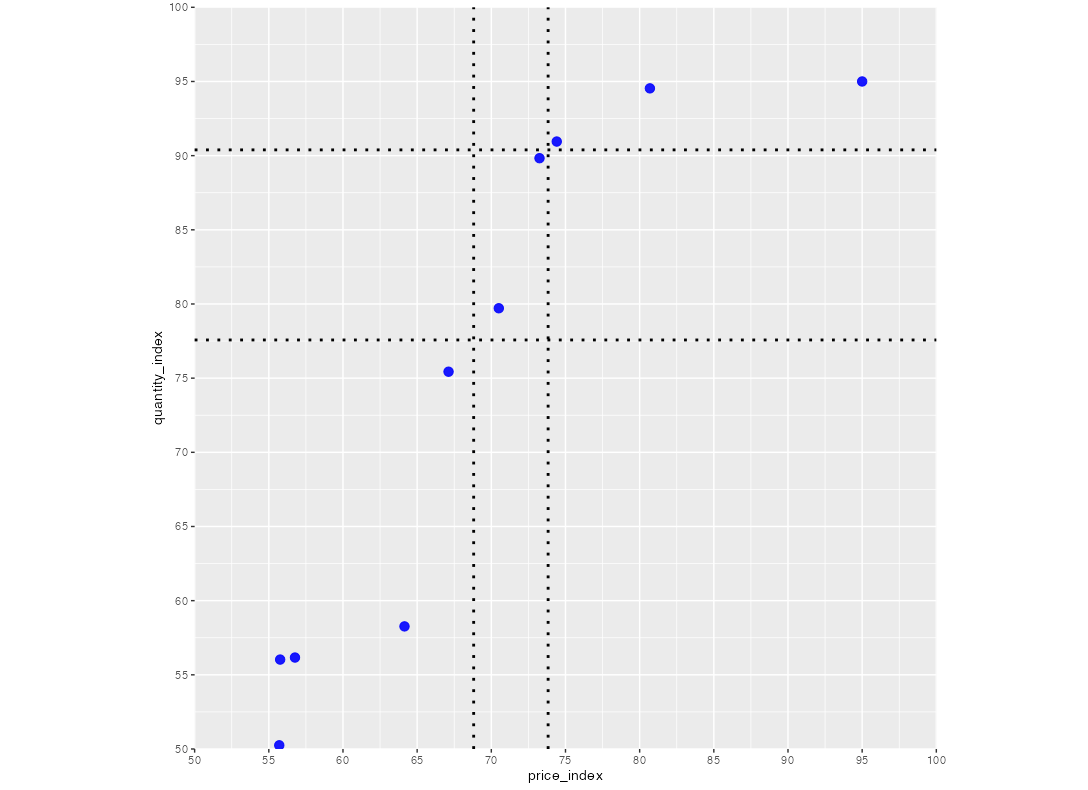
For df, it is assumed that the values of price_index and quantity_index have co-consistency.
products price_index quantity_index price_rank quantity_rank
1 a 95.00000 95.00000 high_price high_volume
2 b 80.69012 94.53585 high_price high_volume
3 c 74.41048 90.95081 high_price high_volume
4 d 73.24853 89.82692 medium_price medium_volume
5 e 70.50442 79.71225 medium_price medium_volume
6 f 67.11609 75.43498 low_price low_volume
7 g 64.14685 58.26419 low_price low_volume
8 h 56.76375 56.16531 low_price low_volume
9 i 55.76472 56.02838 low_price low_volume
10 j 55.70475 50.24873 low_price low_volume
I used the following code to draw a scatter plot, and added two dotted lines to x and y through geom_vline and geom_hline to distinguish top 3, top 5 and the rest of the data points. But now I manually set xintercept = c(68, 74) and yintercept = c(77, 90), how can I automatically set the value? For example: xintercept = c(avg(70.50442, 67.11609), avg(74.41048, 73.24853)) yintercept = c(avg(79.71225, 75.43498), avg(90.95081, 89.82692)). Thanks.
ggplot(df, aes(x = price_index, y = quantity_index, label = products)) +
coord_fixed() +
geom_point(colour = 'blue', size = 3, alpha=0.9) +
scale_x_continuous(expand = c(0, 0), limits = c(50, 100),
breaks = seq(50, 100, 5)
) +
scale_y_continuous(expand = c(0, 0), limits = c(50, 100),
breaks = seq(50, 100, 5)
) +
geom_vline(xintercept = c(68, 74), color='black',
linetype='dotted', size=1) +
geom_hline(yintercept = c(77, 90), color='black',
linetype='dotted', size=1)
Out:
Data samples:
df <- structure(list(products = c("a", "b", "c", "d", "e", "f", "g",
"h", "i", "j"), price_index = c(95, 80.69011538, 74.41047705,
73.24853055, 70.5044217, 67.1160916, 64.14685495, 56.76375355,
55.76472446, 55.70475052), quantity_index = c(95, 94.53585227,
90.95080999, 89.82692004, 79.71224701, 75.43498354, 58.26419203,
56.16530529, 56.02838119, 50.24873055), price_rank = c("high_price",
"high_price", "high_price", "medium_price", "medium_price", "low_price",
"low_price", "low_price", "low_price", "low_price"), quantity_rank = c("high_volume",
"high_volume", "high_volume", "medium_volume", "medium_volume",
"low_volume", "low_volume", "low_volume", "low_volume", "low_volume"
)), class = "data.frame", row.names = c(NA, -10L))
>Solution :
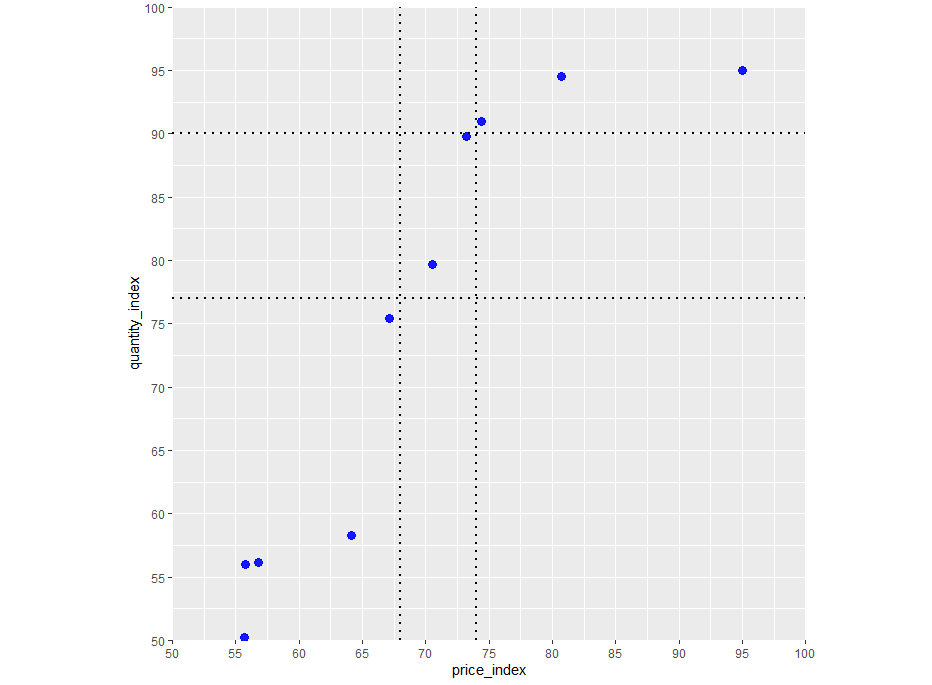
Quite sure the data wrangling could be simplified but this is a quick approach to compute the intercepts for the dividing lines based on the mean:
library(dplyr)
library(ggplot2)
df <- df |>
mutate(
rank = rank(-price_index),
top3 = rank %in% c(3, 4),
top5 = rank %in% c(5, 6)
)
top3 <- df |>
filter(top3) |>
summarise(across(c(price_index, quantity_index), mean))
top5 <- df |>
filter(top5) |>
summarise(across(c(price_index, quantity_index), mean))
top <- list(top3, top5) |> bind_rows()
ggplot(df, aes(x = price_index, y = quantity_index, label = products)) +
coord_fixed() +
geom_point(colour = "blue", size = 3, alpha = 0.9) +
scale_x_continuous(
expand = c(0, 0), limits = c(50, 100),
breaks = seq(50, 100, 5)
) +
scale_y_continuous(
expand = c(0, 0), limits = c(50, 100),
breaks = seq(50, 100, 5)
) +
geom_vline(
data = top, aes(xintercept = price_index), color = "black",
linetype = "dotted", size = 1
) +
geom_hline(
data = top, aes(yintercept = quantity_index), color = "black",
linetype = "dotted", size = 1
)