I have duplicates on the first 3 columns that I would like to keep after pivot_wider transposition, but not in list format.
How to do it?
Initial data with duplicates:
dat0 <-
structure(list(id = c("P1", "P1", "P1", "P1", "P1", "P1", "P1",
"P1", "P1", "P1", "P2", "P2", "P2", "P2", "P2", "P2"), analyte = c("A",
"A", "B", "B", "B", "B", "C", "C", "D", "D", "B", "B", "B", "B",
"D", "D"), analyzer = c("X", "Y", "X", "Y", "X", "Y", "X", "Y",
"X", "Y", "X", "Y", "X", "Y", "X", "Y"), result = c(0.7, 0.9,
1.26, 1.23, 1.24, 1.22, 5.7, 5.3, 4.1, 4.2, 1.22, 1.23, 1.21,
1.22, 4.4, 4.5)), row.names = c(NA, -16L), class = c("tbl_df",
"tbl", "data.frame"))
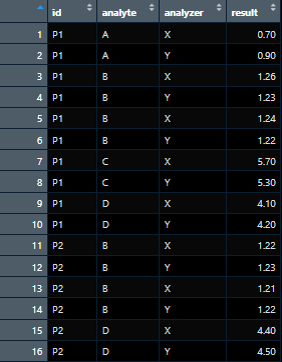
What pivot_wider produces after running, with the following message:
dat1 <- dat0 %>%
pivot_wider(names_from = analyzer, values_from = result)

Values from `result` are not uniquely identified; output will contain list-cols.
• Use `values_fn = list` to suppress this warning.
• Use `values_fn = {summary_fun}` to summarise duplicates.
• Use the following dplyr code to identify duplicates.
{data} |>
dplyr::summarise(n = dplyr::n(), .by = c(id, analyte, analyzer)) |>
dplyr::filter(n > 1L)
Desired output with duplicates:

Thanks for help
>Solution :
You can use row_number() within grouped data to distinguish the duplicates, e.g.,
dat0 %>%
mutate(grp = row_number(), .by = c(id, analyte, analyzer)) %>%
pivot_wider(names_from = analyzer, values_from = result) %>%
select(-grp)
which gives
# A tibble: 8 × 4
id analyte X Y
<chr> <chr> <dbl> <dbl>
1 P1 A 0.7 0.9
2 P1 B 1.26 1.23
3 P1 B 1.24 1.22
4 P1 C 5.7 5.3
5 P1 D 4.1 4.2
6 P2 B 1.22 1.23
7 P2 B 1.21 1.22
Another option is using unnest on top of what you have achieved
dat0 %>%
pivot_wider(names_from = analyzer, values_from = result, values_fn = list) %>%
unnest(cols = c("X", "Y"))
which gives the desired output as well
# A tibble: 8 × 4
id analyte X Y
<chr> <chr> <dbl> <dbl>
1 P1 A 0.7 0.9
2 P1 B 1.26 1.23
3 P1 B 1.24 1.22
4 P1 C 5.7 5.3
5 P1 D 4.1 4.2
6 P2 B 1.22 1.23
7 P2 B 1.21 1.22
8 P2 D 4.4 4.5