How can I determine the confidence/credibility intervals for the posterior estimates of a multi-parameter model?
I can get the confidence interval for each parameter separately.
(Currently using bayestestR, but I don’t mind using something else)
library(dplyr)
library(ggplot2)
library(bayestestR)
N <- 10000
#Posterior samples (random example)
p1 <- rnorm(N)
p2 <- p1 + rnorm(N)
df_post <- tibble(p1,p2)
describe_posterior(
df_post,
centrality = "median",
test = c("p_direction", "p_significance")
)
##Yields:
# Summary of Posterior Distribution
#
# Parameter | Median | 95% CI | pd | ps
# -----------------------------------------------------
# p1 | 0.02 | [-1.85, 2.08] | 50.64% | 0.46
# p2 | -2.24e-03 | [-2.82, 2.78] | 50.04% | 0.47
and I can generate a plot with the points and 2D contours, which gives me a visual indication of the posterior distribution (though I have no idea what % each contour represents):
ggplot(df_post, aes(x=p1, y=p2)) +
geom_density_2d(size=1) +
geom_point(size=0.1)
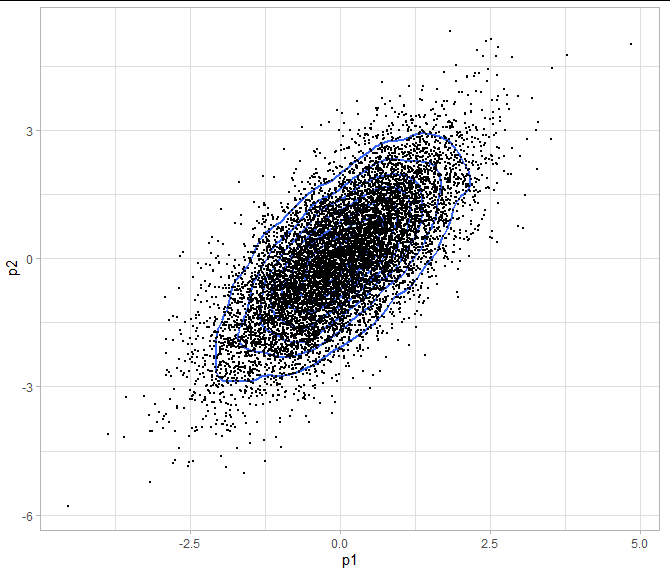
My question is, How can I actually compute (and/or plot) the two dimensional X% credibility interval?
>Solution :
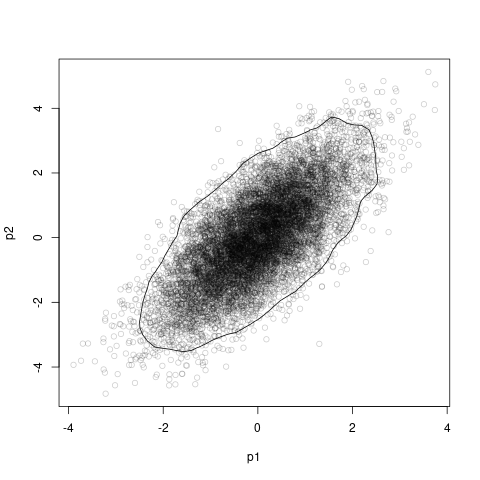
Here’s one base-R-plotting solution, which plots a 95% highest posterior density region based on a 2-D kernel density estimate:
library(emdbook)
library(coda)
HPDregionplot(as.mcmc(df_post))
with(df_post, points(p1, p2, col = adjustcolor("black", alpha.f = 0.2)))
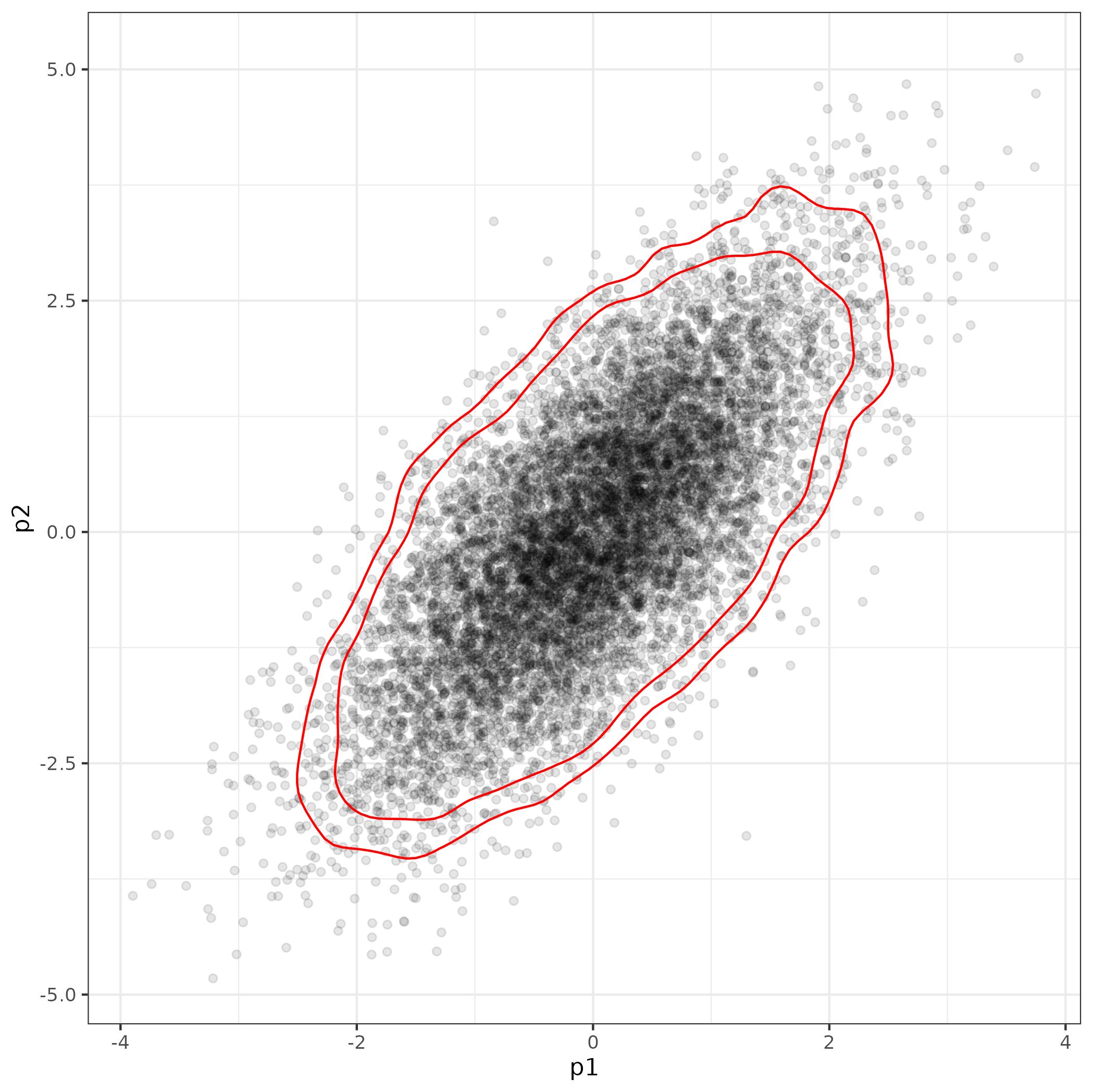
More smoothly/within ggplot:
library(ggplot2); theme_set(theme_bw())
## see function definition below
L <- with(df_post, get_hpd2d_levels(p1, p2))
gg0 <- ggplot(df_post, aes(p1, p2)) + geom_point(alpha=0.1) +
geom_density_2d(breaks = L, colour="red")
print(gg0)
The highest posterior density region is the classical Bayesian approach. If you wanted to head down a rabbit hole, you could look at some of the less-parametric approaches to computing central sets (bag plots, functional depths, etc.). This would be analogous to the difference between a highest posterior density region and a quantile-based credible interval.
##' Get 2D highest posterior density levels corresponding to probability regions
##' @param x x-coordinate of samples
##' @param y y-coordinate
##' @param probs vector of probability levels
##' @param ... arguments for MASS::kde2d
##' @examples
##' dd <- data.frame(x=rnorm(1000), y=rnorm(1000))
##' get_hpd2d_levels(dd$x,dd$y)
##' gg2 <- ggplot(dd, aes(x,y)) + geom_density_2d(breaks=get_hpd2d_levels(dd$x,dd$y), colour="red")
##' print(gg2)
get_hpd2d_levels <- function(x, y, prob=c(0.9,0.95), ...) {
post1 <- MASS::kde2d(x, y)
dx <- diff(post1$x[1:2])
dy <- diff(post1$y[1:2])
sz <- sort(post1$z)
c1 <- cumsum(sz) * dx * dy
## remove duplicates
## dups <- duplicated(sz)
## sz <- sz[!dups]
## c1 <- c1[!dups]
levels <- sapply(prob, function(x) {
approx(c1, sz, xout = 1 - x, ties = mean)$y
})
return(levels)
}