Basically I have this Dataframe:
import pandas as pd
dict = {'number': [1,1,1,1,1,2,2,2,4,4,4,4,6,6], 'time':[34,33,41,36,43,22,24,32,29,28,33,32,55,51]}
df = pd.DataFrame(dict)
print(df)
Output:
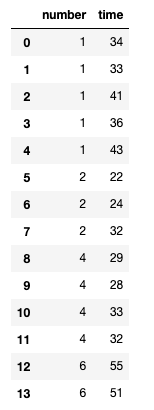
And I want to transform the df or create another one where instead of being several rows with the same 'number', there is a unique 'number' per row; and in the 'time' column, its average (of the records that had the same 'number'). Also, there should be a 3rd column called 'count' that shows the amount of records each 'number' had.
The output expected is:

Thanks.
>Solution :
Simply use groupby + agg:
agg = df.groupby('number')['time'].agg(['count', 'mean']).reset_index()
Output:
>>> agg
number count mean
0 1 5 37.4
1 2 3 26.0
2 4 4 30.5
3 6 2 53.0