I am trying to assess in a sales database whether the # of advertisements has changed.
The example dataframe I am using is as such:
df = pd.DataFrame({"offer-id": [1,1,2,2,3,4,5], "date": ["2024-02-10","2024-02-11","2024-02-10","2024-02-11","2024-02-11","2024-02-11","2024-02-10"], "price": [30,10,30,30,20,25,20]})
And looks like the below:
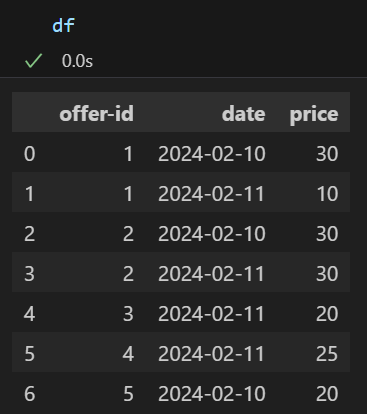
I am now trying to get the # of items that were sold or newly added (I don’t care which one, since once I have one the other should be failry easily computable).
E.g. in a perfect case the next piece of code tells me that on 10th of February 3 offers were online (ID 1, 2, and 5) and one was sold (ID 5)
Or alternatively, it tells me on 11th of February 4 offers are online, and 2 of them are new (from that, since I know the day before 5 were online I can also calculate that one must have sold)
Is there a simple way of doing this?
I have tried things like
df.groupby(['date'])["offer-id"].agg({'nunique'})
but they are missing the "comparison to previous" timestep component.
>Solution :
You could aggregate as a set:
offers = df.groupby('date', sort=True)['offer-id'].agg(set)
date
2024-02-10 {1, 2, 5}
2024-02-11 {1, 2, 3, 4}
Name: offer-id, dtype: object
Then getting the diff will give you the new items:
offers.diff()
date
2024-02-10 NaN
2024-02-11 {3, 4}
Name: offer-id, dtype: object
Or the sold items:
offers.diff(-1)
date
2024-02-10 {5}
2024-02-11 NaN
Name: offer-id, dtype: object
If you want the number of items, chain str.len:
offers.diff().str.len().fillna(0).convert_dtypes()
date
2024-02-10 0
2024-02-11 2
Name: offer-id, dtype: Int64
And to get those as new columns, map:
df['new'] = df['date'].map(offers.diff().str.len().fillna(0).convert_dtypes())
df['sold'] = df['date'].map(offers.diff(-1).str.len().fillna(0).convert_dtypes())
print(df)
Output:
offer-id date price new sold
0 1 2024-02-10 30 0 1
1 1 2024-02-11 10 2 0
2 2 2024-02-10 30 0 1
3 2 2024-02-11 30 2 0
4 3 2024-02-11 20 2 0
5 4 2024-02-11 25 2 0
6 5 2024-02-10 20 0 1