I am trying to scrape some statements made by U.S politicians on votesmart.org
I am experiencing errors in extracting the texts though the code could be run.
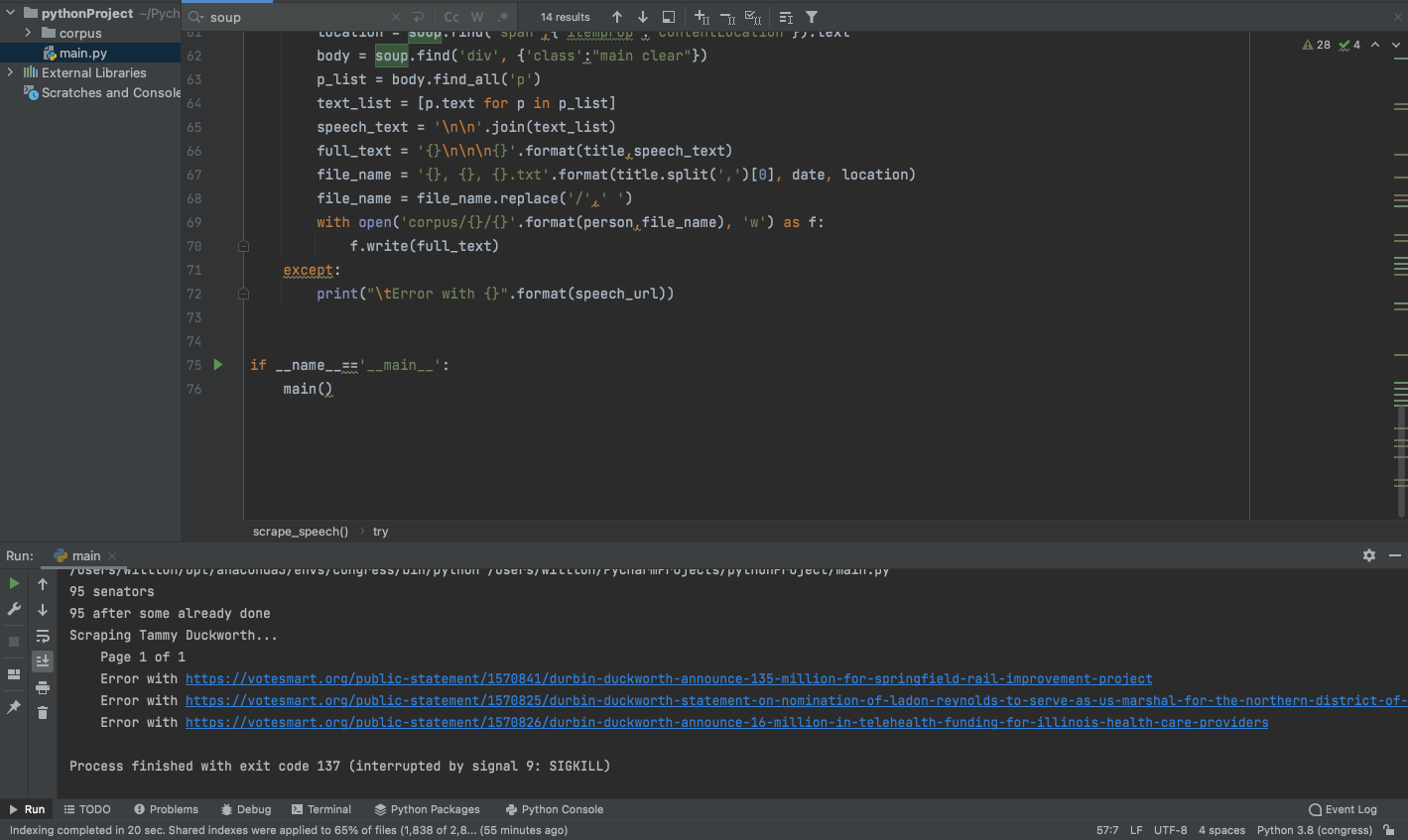
The code that I am using is as follow:
from bs4 import BeautifulSoup
from time import sleep
import pandas as pd
import requests
import os
def main():
df=pd.read_csv('https://theunitedstates.io/congress-legislators/legislators-current.csv')
df = df[df.type=='sen']
df = df[~df.votesmart_id.isna()]
done_list = os.listdir('corpus')
print("{} senators".format(len(df)))
df = df[~df.full_name.isin(done_list)]
print("{} after some already done".format(len(df)))
df = df.sample(frac=1)
df.apply(scrape_politician_speeches,axis=1)
def scrape_politician_speeches(row):
print('Scraping {}...'.format(row.full_name))
vs_url='https://justfacts.votesmart.org/candidate/public-statements/{}'.format(int(row.votesmart_id))
vs_page = requests.get(vs_url) # fill in the last part of the url
soup = BeautifulSoup(vs_page.content, features="lxml")
n_pages = 1
page_num = 1
while page_num <= n_pages:
print("\tPage {} of {}".format(page_num,n_pages))
#speeches_url = vs_page.url + '?start=2019-01-01&speechType=14&p={}'.format(page_num)
speeches_url = vs_page.url + '/?s=date&start=2020/01/01&end=&p={}'.format(page_num)
speeches_page = requests.get(speeches_url)
soup = BeautifulSoup(speeches_page.content, features="lxml")
speech_table = soup.find('table', {'id':'statementsObjectsTables'})
speech_table = soup.find('tbody')
speech_links = speech_table.find_all('a',href=True)
speech_hrefs = [a.get('href') for a in speech_links]
for href in speech_hrefs:
scrape_speech(person=row.full_name, speech_url=href)
try:
n_pages = int(soup.find('h7').text.split()[-1])
except:
print("\tNo page numbers")
pass
page_num += 1
sleep(1)
def scrape_speech(person, speech_url):
try:
if not os.path.isdir('corpus/{}'.format(person)):
os.mkdir('corpus/{}'.format(person))
speech_page = requests.get(speech_url)
soup = BeautifulSoup(speech_page.content,features="lxml")
title = soup.find('h3').text
date = soup.find('span',{'itemprop':'datePublished'}).text
location = soup.find('span',{'itemprop':'contentLocation'}).text
body = soup.find('div', {'class':"main clear"})
p_list = body.find_all('p')
text_list = [p.text for p in p_list]
speech_text = '\n\n'.join(text_list)
full_text = '{}\n\n\n{}'.format(title,speech_text)
file_name = '{}, {}, {}.txt'.format(title.split(',')[0], date, location)
file_name = file_name.replace('/',' ')
with open('corpus/{}/{}'.format(person,file_name), 'w') as f:
f.write(full_text)
except:
print("\tError with {}".format(speech_url))
if __name__=='__main__':
main()
The errors are looking like this:
95 senators
95 after some already done
Scraping Tammy Duckworth...
Page 1 of 1
Error with https://votesmart.org/public-statement/1570841/durbin-duckworth-announce-135-million-for-springfield-rail-improvement-project
Error with https://votesmart.org/public-statement/1570825/durbin-duckworth-statement-on-nomination-of-ladon-reynolds-to-serve-as-us-marshal-for-the-northern-district-of-illinois
Error with https://votesmart.org/public-statement/1570826/durbin-duckworth-announce-16-million-in-telehealth-funding-for-illinois-health-care-providers
Thank you so much for your time and attention. I hope to learn more from this wonderful community.
>Solution :
scrape_speech is outdated, probably pages’ design changed since script was writen, there’s no div.main.clear in html, there’s no <span itemprop="datePublished"> and so on. You need to rewrite it using current css selectors.