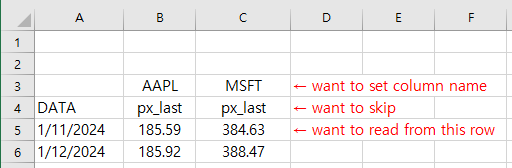
This is my sample external excel file.
I want to set the header(column name) on the 3rd row and read the values starting from the 5th row.
pd.read_excel(file.xlsx, header = [2], skiprows=3)
I tried to using hedaer and skiprows but fail to read correctly.
Is it impossible to do this simultineously when I read it?
>Solution :
You have to wrap the skiprows argument in a list.
from pandas import read_excel
df = read_excel('foo.xlsx', header=[2], skiprows=[3])
print(df)
Results in:
Unnamed: 0 aapl msft
0 1 2 3
1 4 5 6
Giving a number n means "skip n rows", giving a list with numbers means "skip these indices".