I have a small doubt regarding the neg_mean_squared_error of sklearnmetrics.
I am using a regression model Ridge with a cross validation
cross_val_score(estimator, X_train, y_train, cv=5, scoring='neg_mean_squared_error')
i am using different values of alphas to choose to best model.
alphas= (0.01, 0.05, 0.1, 0.3, 0.8, 1, 5, 10, 15, 30, 50)
I calculate the mean value of of the 5 values returned by the cross_val_score and I plotted them in this figure (mean value of the score is the y axis, alphas is the x axis)
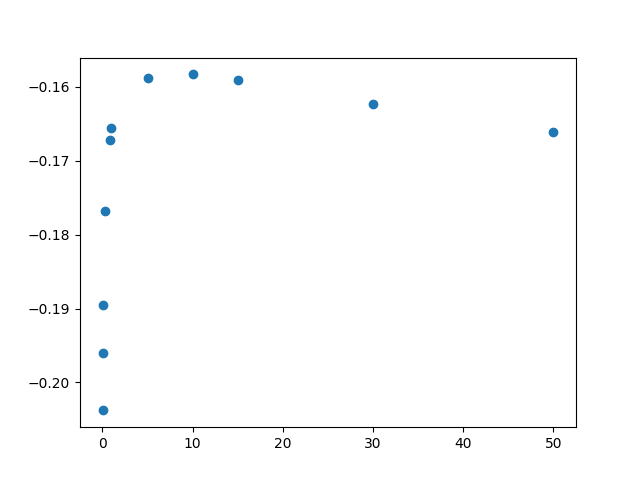
Doing some research I see that with neg_mean_squared_error, we need to look for ‘the smaller the better’
does it mean I have to look for the smallest value "litterally", which would be the first value in my graph, or does it mean the smallest in terms of ‘closest to 0’
in my case all values are negative, that is why i have a doubt about the interpretation
thank you very much
>Solution :
From the docs
All scorer objects follow the convention that higher return values are better than lower return values. Thus metrics which measure the distance between the model and the data, like metrics.mean_squared_error, are available as neg_mean_squared_error which return the negated value of the metric.
So what you want is the maximum of your values, i.e. closest to 0.