Question
I am trying to replace null values in a data frame with the corresponding minimum values for that particular column for a given year (and then replicate for all years).
However my code doesn’t seem to work, could someone inform me why and help form the correct code for this potential use case (my method my not be optimal so open to better process).
Resources
I have added the following code snippet with a sample dataframe and what I am trying to do
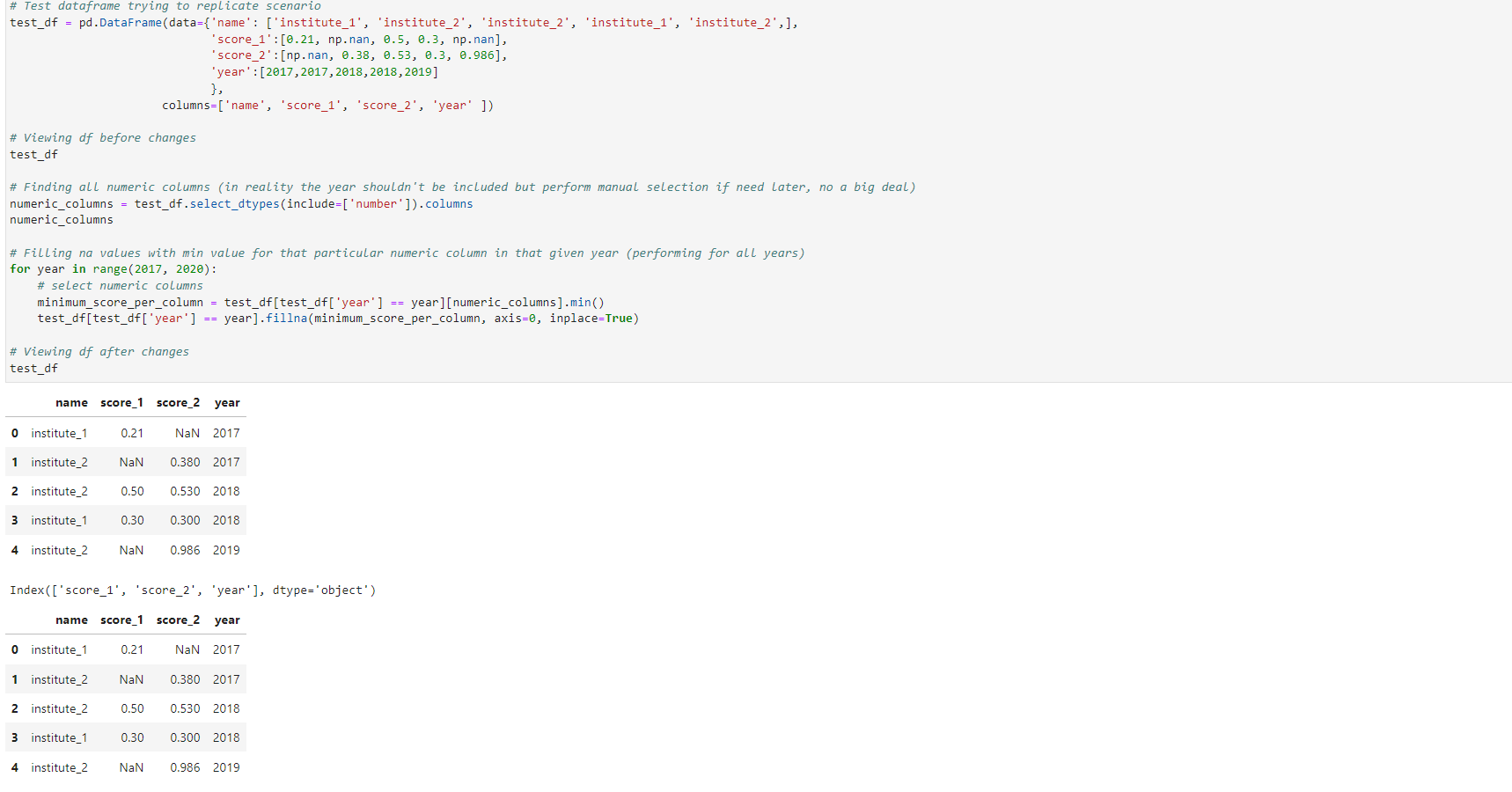
# Test dataframe trying to replicate scenario
test_df = pd.DataFrame(data={'name': ['institute_1', 'institute_2', 'institute_2', 'institute_1', 'institute_2',],
'score_1':[0.21, np.nan, 0.5, 0.3, np.nan],
'score_2':[np.nan, 0.38, 0.53, 0.3, 0.986],
'year':[2017,2017,2018,2018,2019]
},
columns=['name', 'score_1', 'score_2', 'year' ])
# Viewing df before changes
test_df
# Finding all numeric columns (in reality the year shouldn't be included but can perform manual selection if need be later, no a big deal)
numeric_columns = test_df.select_dtypes(include=['number']).columns
numeric_columns
# Filling na values with min value for that particular numeric column in that given year (performing for all years)
for year in range(2017, 2020):
# select numeric columns
minimum_score_per_column = test_df[test_df['year'] == year][numeric_columns].min()
test_df[test_df['year'] == year].fillna(minimum_score_per_column, axis=0, inplace=True)
# Viewing df after changes
test_df
Note : As you can see from the screenshot below the null values haven’t been filled
>Solution :
Because you are doing inplace operation on a sliced data test_df[test_df["year"] == year].
Do manual assignment for the last block:
for year in range(2017, 2020):
# select numeric columns
m = test_df['year'] == year
minimum_score_per_column = test_df[m][numeric_columns].min()
test_df[m] = test_df[m].fillna(minimum_score_per_column, axis=0)
Output:
name score_1 score_2 year
0 institute_1 0.21 0.380 2017
1 institute_2 0.21 0.380 2017
2 institute_2 0.50 0.530 2018
3 institute_1 0.30 0.300 2018
4 institute_2 NaN 0.986 2019