I have two dataframe : df1 and df2. df2 is composed of rows from df1. For each row of df2, I want its index in df1.
For example :
df1 <- data.frame(animal=c('koala', 'hedgehog', 'sloth', 'panda'),
country=c('Australia', 'Italy', 'Peru', 'China'),
avg_sleep_hours=c(21, 18, 17, 10))
df2 <- data.frame(animal=c('koala', 'sloth', 'panda', 'panda'),
country=c('Australia', 'Peru', 'China', 'China'),
avg_sleep_hours=c(21,17,10,10))
I want to get
1 3 4 4
I searched on Internet but found no satisfactory answer, so I wrote my own code.
I know that findIdxRow could return several numbers if a row of df2 is duplicates in df1 but it won’t appear in my data, so I didn’t take the time to deal with that.
findIdxRow <- function(row, df)
{
n <- nrow(df)
is_equal <- sapply(1:n, function(i) all(row==df[i,]))
return(which(is_equal))
}
indexes <- sapply(1:nrow(df2), function(i) findIdxRow(df2[i,],df1))
This code works, but I wonder if there is a shorter way to write it.
>Solution :
A join will be far more performant if your data is more than trivial (~100 rows) size.
In base R:
merge(df2,
df1 |> transform(index = 1:nrow(df1)))$index
Or with dplyr:
library(dplyr)
df2 |>
left_join(df1 |> mutate(index = row_number())) |>
pull(index)
Joining with `by = join_by(animal, country, avg_sleep_hours)`
[1] 1 3 4 4
For anything more than tiny data with a couple hundred rows, either of these will be much, much faster than the match solution. For 1k rows, either one takes under 0.05 seconds, vs. the match solution took 68 seconds, a 1000x speed difference.
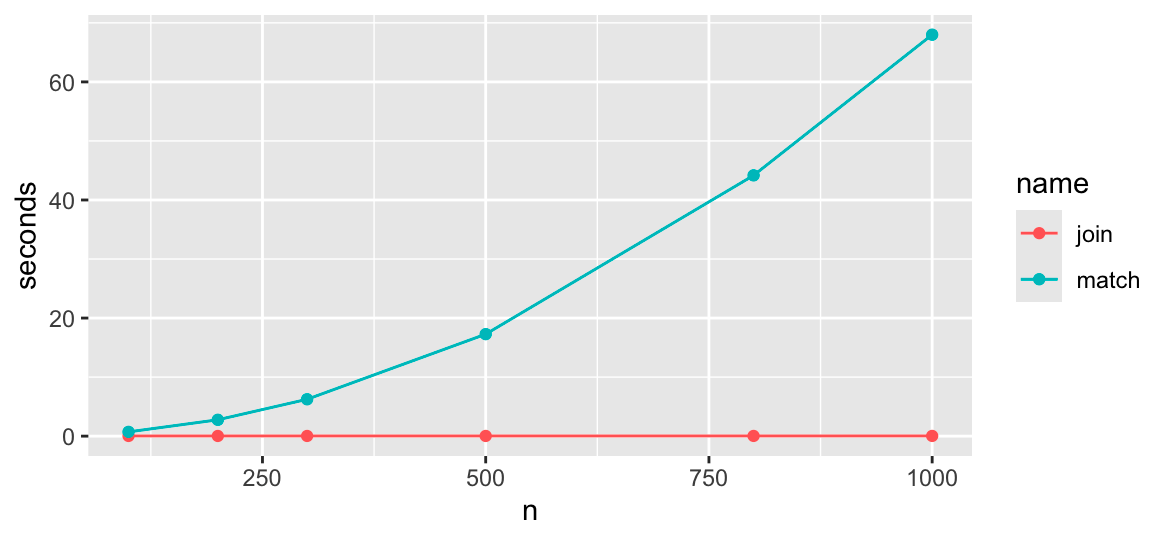
# fake data
set.seed(42)
n <- 1E3
library(dplyr)
df1 <- data.frame(
animal = ids::adjective_animal(n),
country = ids::proquint(n, n_words = 1))
df2 <- df1 |>
slice_sample(n = n)
tictoc::tic()
df2 |>
left_join(df1 |> mutate(index = row_number())) |>
pull(index)
tictoc::toc()
tictoc::tic()
findIdxRow <- function(row, df)
{
n <- nrow(df)
is_equal <- sapply(1:n, function(i) all(row==df[i,]))
return(which(is_equal))
}
indexes <- sapply(1:nrow(df2), function(i) findIdxRow(df2[i,],df1))
tictoc::toc()