I am trying to create a report using pandas pivot table and currently I have below code with this output
df = pd.pivot_table(raw, values=['Shipped','Sold'], index=['Category', 'Model No'], columns=['Customer', 'Week Start Date'], aggfunc=np.sum, fill_value=0)
output

But the output i am desiring is below
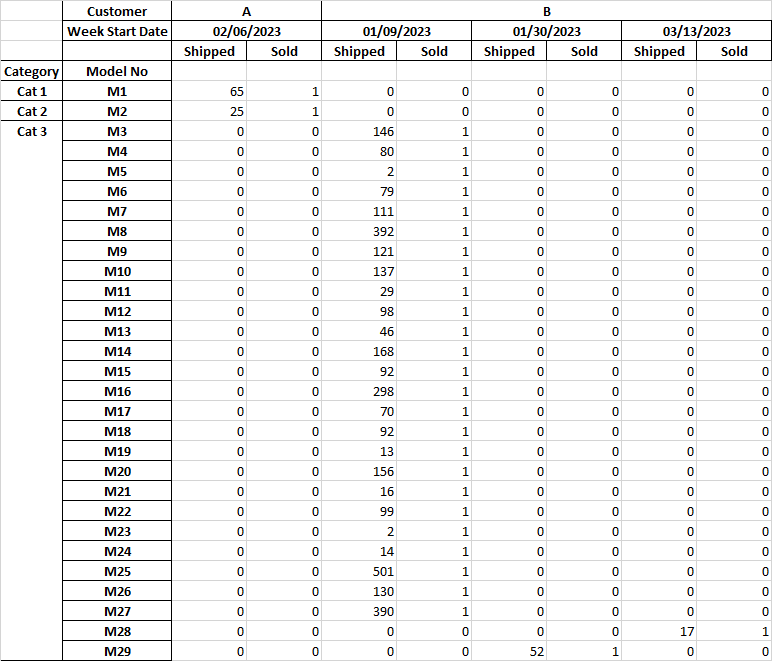
how can i make it like the second report?
thank you!
>Solution :
Use MultiIndex.reorder_levels and then sort the column axis using sort_index with axis=1:
df.columns = df.columns.reorder_levels((1, 2, 0))
df = df.sort_index(axis=1)
Example:
np.random.seed(42)
columns = pd.MultiIndex.from_product(
[['Shipped', 'Sold'], ['A', 'B'], ['d1', 'd2']])
data = np.random.randint(0, 100, size=(5, 8))
df = pd.DataFrame(data, columns=columns)
df
Shipped Sold # level 0
A B A B # level 1
d1 d2 d1 d2 d1 d2 d1 d2 # level 2
0 51 92 14 71 60 20 82 86
1 74 74 87 99 23 2 21 52
2 1 87 29 37 1 63 59 20
3 32 75 57 21 88 48 90 58
4 41 91 59 79 14 61 61 46
# 1st level now 0th, 2nd level now 1st, 0th level now last
df.columns = df.columns.reorder_levels((1, 2, 0))
df = df.sort_index(axis=1)
df
A B
d1 d2 d1 d2
Shipped Sold Shipped Sold Shipped Sold Shipped Sold
0 51 60 92 20 14 82 71 86
1 74 23 74 2 87 21 99 52
2 1 1 87 63 29 59 37 20
3 32 88 75 48 57 90 21 58
4 41 14 91 61 59 61 79 46
For posterity I’ll also include the option by Quang Hoang in the comments using stack / unstack:
df.stack(0).unstack(-1)
A B
d1 d2 d1 d2
Shipped Sold Shipped Sold Shipped Sold Shipped Sold
0 51 60 92 20 14 82 71 86
1 74 23 74 2 87 21 99 52
2 1 1 87 63 29 59 37 20
3 32 88 75 48 57 90 21 58
4 41 14 91 61 59 61 79 46
Although note that this is generally not a very performant option since it has to actually reshape your DataFrame.