I am new to web scraping. I am trying to web scrap a website called https://www.bproperty.com/
Here I am trying to get all the data from all the pages of one specific area.(You will get an idea after going to the link : https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/) In the link at the bottom you will be able to see the pagination. So I tried to take all the urls in an array and loop through them and scrapped the data and imported to CSV. In the terminal window all the data are showing find but While trying to import it to the CSV I can only see 4 rows.
Here Is my code:
from bs4 import BeautifulSoup
import requests
from csv import writer
urls = [
"https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/"
"https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/page-2/",
"https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/page-3/",
"https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/page-4/",
"https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/page-5/",
"https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/page-6/",
"https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/page-7/",
"https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/page-8/",
"https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/page-9/",
"https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/page-10/",
"https://www.bproperty.com/en/dhaka/apartments-for-rent-in-gulshan/page-11/"
]
for u in urls:
page = requests.get(u)
soup = BeautifulSoup(page.content, 'html.parser')
lists = soup.find_all('article', class_="ca2f5674")
with open("bproperty-gulshan.csv", 'w', encoding="utf8", newline='') as f:
wrt = writer(f)
header = ["Title", "Location", "Price", "type", "Beds", "Baths", "Length"]
wrt.writerow(header)
for list in lists:
price = list.find('span', class_="f343d9ce").text.replace("/n", "")
location = list.find('div', class_="_7afabd84").text.replace("/n", "")
type = list.find('div', class_="_9a4e3964").text.replace("/n", "")
title = list.find('h2', class_="_7f17f34f").text.replace("/n", "")
beds = list.find('span', class_="b6a29bc0").text.replace("/n", "")
baths = list.find('span', class_="b6a29bc0").text.replace("/n", "")
length = list.find('span', class_="b6a29bc0").text.replace("/n", "")
info = [title, location, price, type, beds, baths, length]
wrt.writerow(info)
print(info)
Here is my CSV
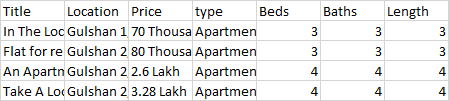
So actually I want to show the pages data withing one script. Is there any way to do this or is there any way to solve this issue?
>Solution :
list and type is a data structure type in python. Do not use them as variable name.
Using them as a variable name will mask the built-in function "type" and "list" within the scope of the block. So while doing so does not raise a SyntaxError, it is not considered good practice, and I would avoid doing so.
Also since you are opening and closing the file in the same loop, use append mode.
The below code should work fine :
for u in urls:
page = requests.get(u)
soup = BeautifulSoup(page.content, 'html.parser')
lists = soup.find_all('article', class_="ca2f5674")
with open("bproperty-gulshan.csv", 'a', encoding="utf8", newline='') as f:
wrt = writer(f)
header = ["Title", "Location", "Price", "type", "Beds", "Baths", "Length"]
wrt.writerow(header)
for list_ in lists:
price = list_.find('span', class_="f343d9ce").text.replace("/n", "")
location = list_.find('div', class_="_7afabd84").text.replace("/n", "")
type_ = list_.find('div', class_="_9a4e3964").text.replace("/n", "")
title = list_.find('h2', class_="_7f17f34f").text.replace("/n", "")
beds = list_.find('span', class_="b6a29bc0").text.replace("/n", "")
baths = list_.find('span', class_="b6a29bc0").text.replace("/n", "")
length = list_.find('span', class_="b6a29bc0").text.replace("/n", "")
info = [title, location, price, type_, beds, baths, length]
wrt.writerow(info)
print(info)
which gives us
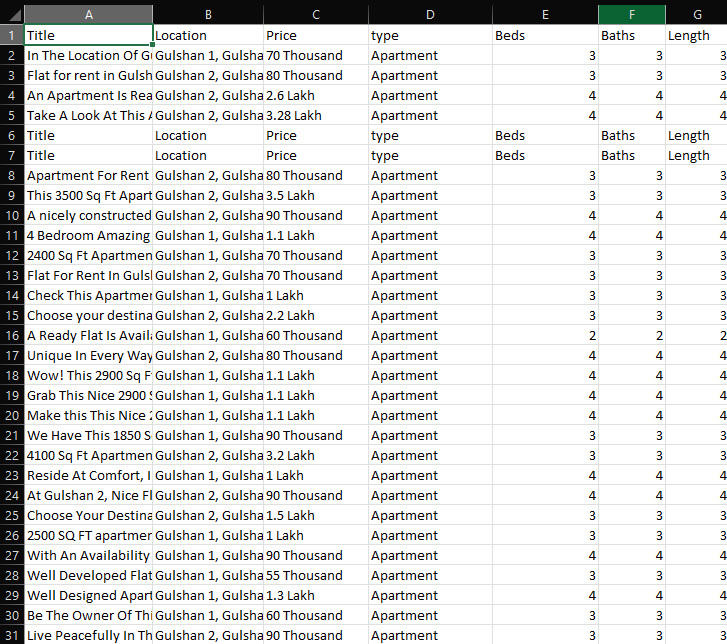
Keep in mind your headers are written everytime you open the file, so its better you open the handle to the file only once and close once you are done processing in the loop.