This is my DataFrame:
import pandas as pd
df = pd.DataFrame({
'a': [10, 20, 30, 50, 50, 50, 4, 100],
'b': [30, 3, 200, 25, 24, 31, 29, 2],
'd': list('aaabbbcc')
})
Expected output:
a b d
0 10 30 a
1 20 3 a
2 30 200 a
The grouping is by column d. I want to return the groups that have at least two instances of this mask
m = (df.b.gt(df.a))
This is what I have tried. It works but I wonder if there is a better/more efficient way to do it.
out = df.groupby('d').filter(lambda x: len(x.loc[x.b.gt(x.a)]) >= 2)
>Solution :
With pandas
You could use a groupby.transform on the mask with sum to produce a boolean Series:
m = df['b'].gt(df['a'])
out = df[m.groupby(df['d']).transform('sum').ge(2)]
Output:
a b d
0 10 30 a
1 20 3 a
2 30 200 a
Intermediates:
a b d m transform('sum') ge(2)
0 10 30 a True 2 True
1 20 3 a False 2 True
2 30 200 a True 2 True
3 50 25 b False 0 False
4 50 24 b False 0 False
5 50 31 b False 0 False
6 4 29 c True 1 False
7 100 2 c False 1 False
Alternative:
counts = m.groupby(df['d']).sum()
out = df[df['d'].isin(counts.index[counts>=2])]
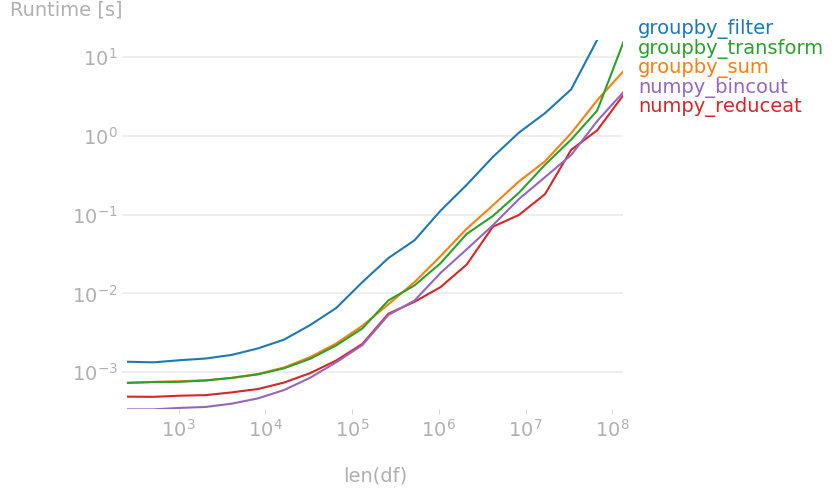
With numpy
Alternatively, one could avoid the costly groupby with pure numpy.
This first approach with add.reduceat requires the groups to be consecutive:
groups = df['d'].ne(df['d'].shift()).values
m = df['b'].gt(df['a']).values
idx = np.nonzero(groups)[0]
out = df[df['d'].isin(df['d'].iloc[idx[np.add.reduceat(m, idx)>=2]])]
This second one with pandas.factorize and numpy.bincount would work even with shuffled groups:
a, idx = pd.factorize(df['d'])
out = df[df['d'].isin(idx[np.bincount(a, weights=m) >= 2])]
timings