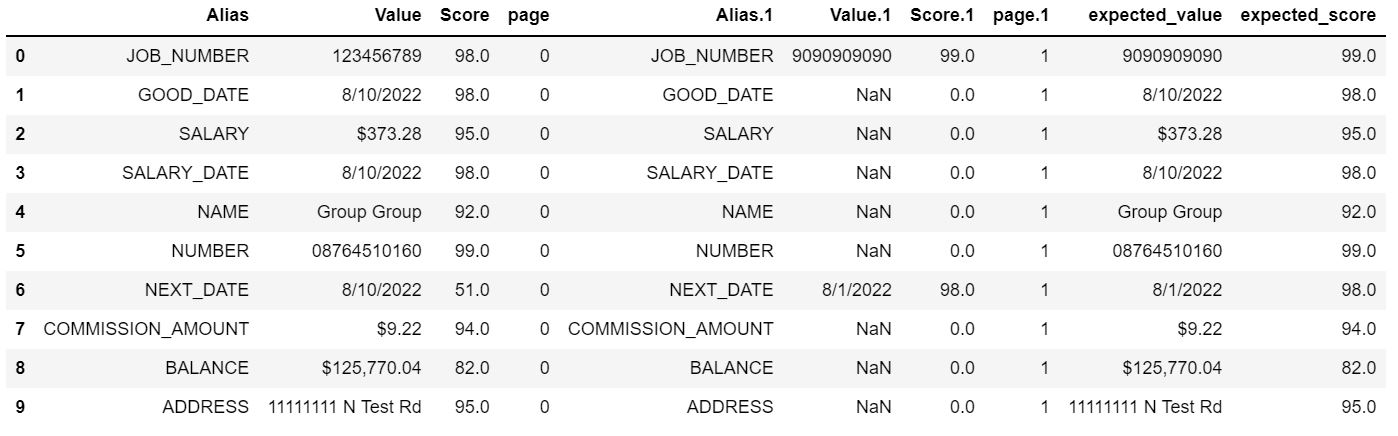
Need to create 2 new column(expected_value and expected_score) by identifying maximum score between Score and Score.1 and returning corresponding value from Value and Value.1 columns whose score is that maximum.
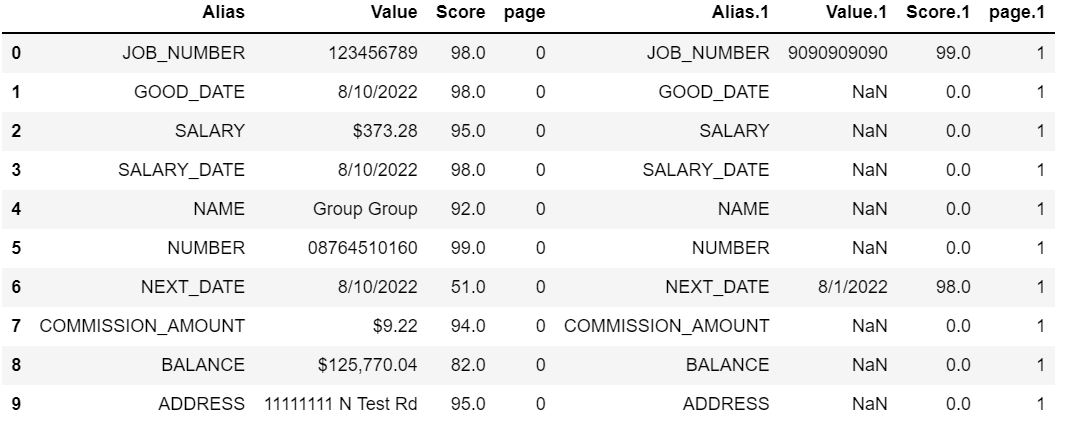
dict = {'Alias': ['JOB_NUMBER','GOOD_DATE','SALARY','SALARY_DATE','NAME','NUMBER','NEXT_DATE','COMMISSION_AMOUNT',
'BALANCE','ADDRESS'],'Value': ['123456789','8/10/2022','$373.28','8/10/2022','Group Group','08764510160','8/10/2022','$9.22','$125,770.04','11111111 N Test Rd'],'Score': [98.0,98.0,95.0,98.0,92.0,99.0,51.0,94.0,82.0,95.0],'page': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0],'Alias.1': ['JOB_NUMBER','GOOD_DATE','SALARY','SALARY_DATE','NAME','NUMBER','NEXT_DATE',
'COMMISSION_AMOUNT','BALANCE','ADDRESS'],'Value.1': [9090909090,np.nan,np.nan,np.nan,np.nan,
np.nan,'8/1/2022',np.nan,np.nan,np.nan],'Score.1': [99.0,0.0,0.0,0.0,0.0,0.0,98.0,0.0,0.0,0.0],
'page.1': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
df = pd.DataFrame(dict)
Original DataFrame:
Expected Result:
My Attempt not able to make any inroad:
# column name with max duration value
max_col_name = df.filter(like='Score', axis=1).max(axis = 1).idxmax()
# index of max_col_name
max_col_idx =df.columns.get_loc(max_col_name)
# row index of max value in max_col_name
max_row_idx = df[max_col_name].idxmax()
# output with .loc
df.iloc[max_row_idx, [0, max_col_idx, max_col_idx + 1 ]]
>Solution :
With dynamic columns for Score (e.g. Score, Score.1, Score.2 … Score.n) and same with Value columns, try as follows:
# don't use "dict" as a variable to store a `dict`, it will overwrite
# its built-in functionality!
df = pd.DataFrame(my_dict)
# group all cols that start with `Score`|`Value`
scores = df.filter(like='Score', axis=1).columns
values = df.filter(like='Value', axis=1).columns
# create a mask with `True` for each cell in `df[scores]` that
# matches the max of its row (`axis=1`)
max_values = df[scores].max(axis=1)
m = df[scores].eq(max_values, axis=0).to_numpy()
# apply (inverse of) mask to `df[values]` and fill up any `NaN` value
# in 1st column with the first value that is found in 2nd, 3rd, etc column
# and then select only that first column; will now always be filled
df['expected_value'] = df[values].mask(~m).fillna(method='bfill', axis=1).iloc[:,0]
df['expected_score'] = max_values
print(df)
Alias Value ... expected_value expected_score
0 JOB_NUMBER 123456789 ... 9090909090 99.0
1 GOOD_DATE 8/10/2022 ... 8/10/2022 98.0
2 SALARY $373.28 ... $373.28 95.0
3 SALARY_DATE 8/10/2022 ... 8/10/2022 98.0
4 NAME Group Group ... Group Group 92.0
5 NUMBER 08764510160 ... 08764510160 99.0
6 NEXT_DATE 8/10/2022 ... 8/1/2022 98.0
7 COMMISSION_AMOUNT $9.22 ... $9.22 94.0
8 BALANCE $125,770.04 ... $125,770.04 82.0
9 ADDRESS 11111111 N Test Rd ... 11111111 N Test Rd 95.0