I have a (for me) difficult idea for my dataframe
# A tibble: 6 x 28
Full.Name `1_2019` `1_2020` `10_2019` `10_2020` `11_2019` `11_2020` `12_2019` `12_2020` `2_2019` `2_2020`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Adena T.~ -0.383 -0.216 -0.330 -0.602 -0.426 -0.266 -0.361 -0.253 -0.290 -0.401
2 Albert B~ -1.06 -0.195 -0.321 -0.535 -0.516 -0.308 -0.475 -0.328 -1.01 -0.443
3 Christop~ -0.0842 -0.217 -0.259 0.251 -0.340 -0.163 -0.275 -0.00184 -0.164 -0.339
4 Colin M.~ -1.06 -0.0936 -0.166 -0.570 -0.0989 -0.311 -0.0126 -0.386 -1.01 0.120
5 Derek J.~ -0.0993 -0.153 0.192 -0.110 -0.0643 -0.145 0.0424 -0.169 -0.00159 1.20
6 Eileen P~ 0.580 -0.0270 0.0469 0.759 0.302 0.320 0.402 0.0158 -0.440 0.992
# ... with 17 more variables: `3_2019` <dbl>, `3_2020` <dbl>, `4_2019` <dbl>, `4_2020` <dbl>,
# `5_2019` <dbl>, `5_2020` <dbl>, `6_2019` <dbl>, `6_2020` <dbl>, `7_2019` <dbl>, `7_2020` <dbl>,
# `8_2019` <dbl>, `8_2020` <dbl>, `9_2019` <dbl>, `9_2020` <dbl>, Entity <chr>, Ticker.Symbol <chr>,
# Ra <dbl>
I want to create a table, which gives out the max for each time-column [2:25], but I don’t only want to include the value for the max, but I want to show the Full.Name value for the corresponding max value. The output should look like this:
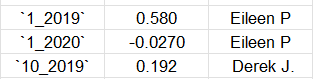
Is that even possible within the R envorimnent? This greatly exeeds my knowledge of R and is a real specific problem.
An alternative would be to count how many times a Full.Name has a max value for the mentioned columns. The output here should look like this:
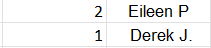
Depending on what is better/easier to do – both solutions would satisfy my needs, but the first one is preffered, if possible.
Any help is appreciated. Thanks!
This is the dput() output:
structure(list(Full.Name = c("Adena T. Friedman", "Albert Bourla, D.V.M., DVM, Ph.D.",
"Christopher A. Caldwell", "Colin M. Angle", "Derek J. Leathers",
"Eileen P. Drake"), 1_2019 = c(-0.383055707155795, -1.05904949909804,
-0.0842258334645898, -1.05904949909804, -0.0992767433029089,
0.579723329852852), 1_2020 = c(-0.216468956246416, -0.195482903945435,
-0.217062894420478, -0.0935901304701391, -0.153203397403474,
-0.0269547804807655), 10_2019 = c(-0.330254033944817, -0.320924627792365,
-0.259035596196796, -0.165521585779242, 0.191622624792709, 0.0468503831648096
), 10_2020 = c(-0.602152189359244, -0.535418283344491, 0.250595906332612,
-0.569859279903607, -0.110044980526754, 0.758921953633378), 11_2019 = c(-0.426305396694651,
-0.515785519108897, -0.339519299471372, -0.0989134193907651,
-0.0643284748215571, 0.302353842370004), 11_2020 = c(-0.266358518183409,
-0.307946402525424, -0.163463742373844, -0.311354999046801, -0.145418823259319,
0.319519922634799), 12_2019 = c(-0.360807066616068, -0.475346190769451,
-0.275106046438998, -0.0126324599828461, 0.0423954161102351,
0.402048846748391), 12_2020 = c(-0.252841249834664, -0.327543659166096,
-0.0018365708720592, -0.385790707531874, -0.168610938237114,
0.0157769121978877), 2_2019 = c(-0.289816736567697, -1.01038671729134,
-0.163531276028501, -1.01038671729134, -0.00158874427823888,
-0.439935482551789), 2_2020 = c(-0.400669734118479, -0.443383016682402,
-0.33938545913546, 0.119970547944465, 1.19680703377221, 0.992446784767351
), 3_2019 = c(-0.282321826547816, -0.663729475667504, -0.143945270922075,
-0.663729475667504, -0.21135343810465, -0.0113472595074246),
3_2020 = c(0.210034583053767, -0.119257597883072, 0.0604507532275685,
-0.0156610190075263, 0.244957142838736, 0.931989699546531
), 4_2019 = c(-0.0943196744817198, -1.40545668795108, -0.242173427911943,
-1.40545668795108, -0.308396700646459, 0.328421577075603),
4_2020 = c(-0.603468919897277, -0.46742517184902, 0.458562501566214,
-0.415513741672711, -0.0675211576243626, 1.33393253995762
), 5_2019 = c(-0.129921217468993, -1.43714052178394, -0.141050793589322,
-1.43714052178394, 0.0899785102237378, 0.282749974677489),
5_2020 = c(-0.108187683872424, -0.487161950868388, -0.383969978742953,
-0.452015143848601, -0.128294552876879, 1.31749515416976),
6_2019 = c(-0.148193355904154, -1.28016746608286, -0.44221260530122,
-0.258433114852674, -0.218530887721297, 0.116423968553205
), 6_2020 = c(-0.746183120363155, -0.551046867139016, 0.437251904764289,
-0.311162387486119, 0.384217485429955, 1.81560563991272),
7_2019 = c(-0.345861092486428, -0.42039491332283, -0.177019171816214,
-0.0648826509182595, -0.28646337065065, -0.0977527167183953
), 7_2020 = c(-0.288166498436476, -0.288339408366061, -0.206961079106134,
-0.177119025931579, -0.197207687539335, 0.144917519117581
), 8_2019 = c(-0.364262512827361, -0.245902656766371, -0.20578067166095,
0.0553125457840526, -0.328962204879346, -0.092965764103294
), 8_2020 = c(-0.395704012557836, -0.413354561981113, -0.254541944628269,
-0.162952100829554, -0.0979980789518939, 0.688768946608496
), 9_2019 = c(-1.34762262072134, -0.0330072964653664, -0.436255871711975,
-0.0372309601577549, -0.188601863828996, 0.208072109502548
), 9_2020 = c(-0.464351916504254, -0.240626492556919, -0.116659195276997,
-0.616441955671251, -0.279371793278997, 0.735245489136106
), Entity = c("NASDAQ INC", "PFIZER INC", "CONCENTRIX CORP -SPN",
"IROBOT CORP", "WERNER ENTERPRISES INC", "AEROJET ROCKETDYNE HOLDINGS"
), Ticker.Symbol = c("NDAQ", "PFE", "CNXC", "IRBT", "WERN",
"AJRD"), Ra = c(0.559536371978057, 0.0400867733394902, 0.241250053137799,
0.376713156282756, 0.458131711187552, 0.636418544760744)), row.names = c(NA,
-6L), class = c("tbl_df", "tbl", "data.frame"))
>Solution :
You could reshape your data to long format (with dplyr::pivot_longer, for example) and then filter only the rows with the maximum value, among those grouped_by month:
library(tidyr)
library(dplyr)
dat |>
pivot_longer(-Full.Name, names_to = "month") |>
group_by(month) |>
filter(value == max(value))
Output
#> # A tibble: 10 × 3
#> # Groups: month [10]
#> Full.Name month value
#> <chr> <chr> <dbl>
#> 1 DerekJ.~ `10_2019` 0.192
#> 2 DerekJ.~ `2_2019` -0.00159
#> 3 DerekJ.~ `2_2020` 1.2
#> 4 EileenP~ `1_2019` 0.58
#> 5 EileenP~ `1_2020` -0.027
#> 6 EileenP~ `10_2020` 0.759
#> 7 EileenP~ `11_2019` 0.302
#> 8 EileenP~ `11_2020` 0.32
#> 9 EileenP~ `12_2019` 0.402
#> 10 EileenP~ `12_2020` 0.0158
Created on 2022-06-16 by the reprex package (v2.0.1)