I have a .txt file that is in .json format that I am trying to read into a pandas dataframe. I have figured out how to put the data into the dataframe. However, the data does not have column names. I’m not sure how to pull the column names from the .txt file into the dataframe. This feels like it should be something easy. How do I get the column names added to my dataframe from the .txt file?
Here is the code I’m using to read the .txt file into a datframe and the result:
import pandas as pd
import json
with open("response_1689779574197.txt",'r') as f:
data = json.loads(f.read())
df = pd.json_normalize(data, record_path =['data'])
df
Here is the result I’m getting:
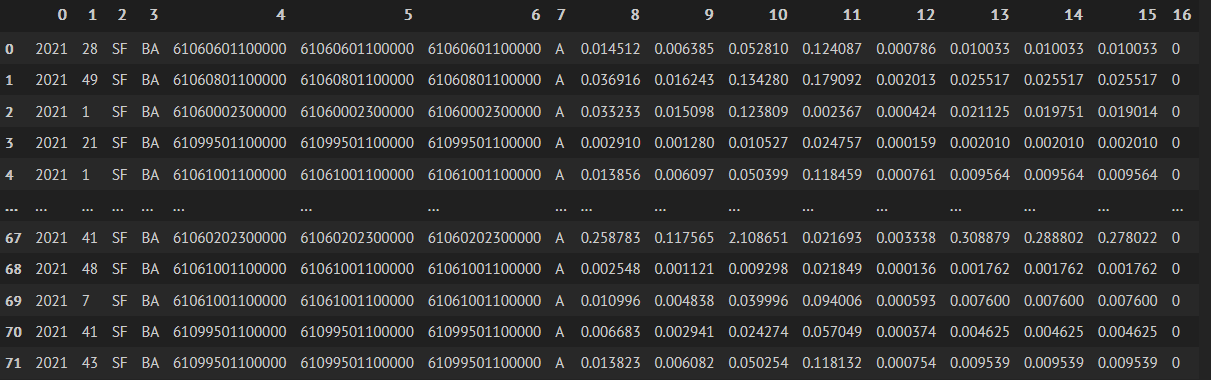
Here is a portion of the .txt file in .json format:
{"name": "emissions_detail", "description": "Emissions by yr-co-ab-dis-scc-sic-eic-type.", "parameters": {"output_type": ["json-d"], "ab": ["SF"], "yr": ["2021"], "adjusted": "true", "eicsum": ["610"], "vintage": "2019O3SIP104"}, "columns": ["yr", "co", "ab", "dis", "scc", "sic", "eic", "type", "tog", "rog", "cot", "nox", "sox", "pm", "pm10", "pm2_5", "nh3"], "data": [[2021, 28, "SF", "BA", 61060601100000, 61060601100000, 61060601100000, "A", 0.01451223, 0.00638538, 0.05280983, 0.12408738, 0.00078586, 0.01003282, 0.01003282, 0.01003282, 0], [2021, 49, "SF", "BA", 61060801100000, 61060801100000, 61060801100000, "A", 0.03691642, 0.01624322, 0.13427958, 0.17909172, 0.00201315, 0.0255173, 0.0255173, 0.0255173, 0], [2021, 1, "SF", "BA", 61060002300000, 61060002300000, 61060002300000, "A", 0.03323321, 0.01509785, 0.12380935, 0.0023666, 0.00042357, 0.02112457, 0.01975147, 0.01901423, 0], [2021, 21, "SF", "BA", 61099501100000, 61099501100000, 61099501100000, "A", 0.00290951, 0.00128018, 0.01052713, 0.02475726, 0.0001587, 0.00201021, 0.00201021, 0.00201021, 0], [2021, 1, "SF", "BA", 61061001100000, 61061001100000, 61061001100000, "A", 0.0138564, 0.00609682, 0.05039926, 0.11845864, 0.00076074, 0.00956363, 0.00956363, 0.00956363, 0], [2021, 7, "SF", "BA", 61060612200000, 61060612200000, 61060612200000, "A", 0.00035728, 0.00033799, 0.00077261, 0.00273762, 0.01070932, 0.00035728, 0.00034871, 0.00034549, 0], [2021, 49, "SF", "BA", 61099501200000, 61099501200000, 61099501200000, "A", 0.00249041, 0.00178064, 0.00643835, 0.03093969, 0.00186849, 0.00093425, 0.00093425, 0.00093425, 0], [2021, 28, "SF", "BA", 61060002300000, 61060002300000, 61060002300000, "A", 0.23334067, 0.10600667, 0.86931211, 0.01661325, 0.00297842, 0.14832245, 0.13868149, 0.13350504, 0], [2021, 48, "SF", "BA", 61060202300000, 61060202300000, 61060202300000, "A", 0.31589931, 0.14351306, 2.574049, 0.02648095, 0.00407355, 0.3770507, 0.3525424, 0.33938334, 0], [2021, 21, "SF", "BA", 61060612200000, 61060612200000, 61060612200000, "A", 0.00033271, 0.00031474, 0.00072125, 0.00255005, 0.00997691, 0.00033271, 0.00032472, 0.00032173, 0], [2021, 7, "SF", "BA", 61099501100000, 61099501100000, 61099501100000, "A", 0.00994501, 0.0043758, 0.03614162, 0.08495031, 0.00053902, 0.00687257, 0.00687257, 0.00687257, 0], [2021, 43, "SF", "BA", 61060202300000, 61060202300000, 61060202300000, "A", 1.20922554, 0.54935116, 9.85313606, 0.1013649, 0.01559504, 1.44330525, 1.34949041, 1.29911906, 0], [2021, 28, "SF", "BA", 61099501100000, 61099501100000, 61099501100000, "A", 0.0011526, 0.00050714, 0.00424365, 0.00995423, 0.00005239, 0.00081206, 0.00081206, 0.00081206, 0], [2021, 48, "SF", "BA", 61060801100000, 61060801100000, 61060801100000, "A", 0.02352946, 0.01035296, 0.08560602, 0.1141775, 0.00127406, 0.0162646, 0.0162646, 0.0162646, 0]]}
Here is what the result I’m trying to get:

>Solution :
I think you can also access the specific json properties (columns/data) like this:
data = json.loads(your_json_file)
columns = data['columns']
data_rw= data['data']
df = pd.DataFrame(data_rw, columns=columns)