Create a list from generator expression:
V = [('\\u26' + str(x)) for x in range(63,70)]
First issue: if you try to use just "\u" + str(...) it gives a decoder error right away. Seems like it tries to decode immediately upon seeing the \u instead of when a full chunk is ready. I am trying to work around that with double backslash.
Second, that creates something promising but still cannot actually print them as unicode to console:
[ipython3]: print([v[0:] for v in V])
['\\u2663', '\\u2664', '\\u2665', .....]
[ipython3]: print(V[0])
\u2663
What I would expect to see is a list of symbols that look identical to when using commands like u"\u0123" such as:
`print(u'\u2663')

(Screenshot of "Clubs" symbol output is attached since SO unclear on how to show unicode either)
Any way to do that from a generated list? Or is there a better way to print them instead of the u"\u0123" format?
Edit: this screenshot is NOT what I want:

^^ I want to see the actual symbols drawn, not the unicode values.
Edit: Thanks for the great insight from [@Panagiotis Kanavos] in the accepted answer! I am posting screenshot of result because it won’t let me do so in a comment under your answer:
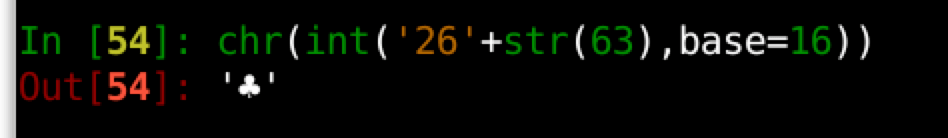
In [54]: chr(int('26'+str(63),base=16))
That prints beautifully. Just needed the ‘base16’ part in this case to get the clubs symbol from 2663.
>Solution :
Unicode is a character to bytes encoding, not escape sequences. Python 3 strings are Unicode. To return the character that corresponds to a Unicode code point use chr :
chr(i)
Return the string representing a character whose Unicode code point is the integer i. For example, chr(97) returns the string ‘a’, while chr(8364) returns the string ‘€’. This is the inverse of ord().The valid range for the argument is from 0 through 1,114,111 (0x10FFFF in base 16). ValueError will be raised if i is outside that range.
To generate the characters between 2663 and 2670:
>>> [chr(x) for x in range(2663,2670)]
['੧', '੨', '੩', '੪', '੫', '੬', '੭']
Escape sequences use hexadecimal notation though. 0x2663 is 9827 in decimal, and 0x2670 becomes 9840.
>>> [chr(x) for x in range(9827,9840)]
['♣', '♤', '♥', '♦', '♧', '♨', '♩', '♪', '♫', '♬', '♭', '♮', '♯']
You can use also use hex numeric literals:
>>> [chr(x) for x in range(0x2663,0x2670)]
['♣', '♤', '♥', '♦', '♧', '♨', '♩', '♪', '♫', '♬', '♭', '♮', '♯']
or, to use exactly the same logic as the question
[chr(0x2600 + x) for x in range(0x63,0x70)]
[‘♣’, ‘♤’, ‘♥’, ‘♦’, ‘♧’, ‘♨’, ‘♩’, ‘♪’, ‘♫’, ‘♬’, ‘♭’, ‘♮’, ‘♯’]
The reason the original code doesn’t work is that escape sequences are used to represent a single character in a string when we can’t or don’t want to type the character itself. The interpreter or compiler replaces them with the corresponding character immediatelly. The string \\u26 is an escaped \ followed by u, 2 and 6:
>>> len('\\u26')
4